⚠️ You may only use public data sets (UCSF P1-P2 classification) on Wynton as of 2026-01-30.
UCSF Wynton HPC Status #
Queue Metrics #
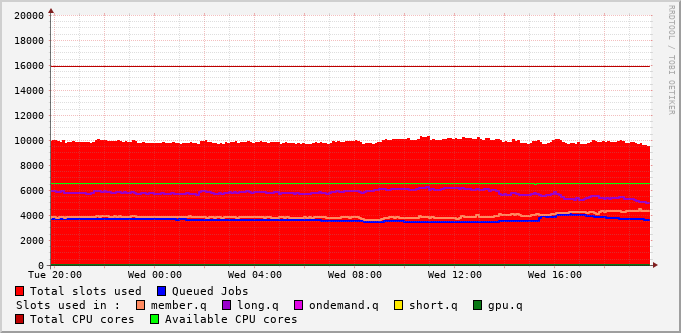
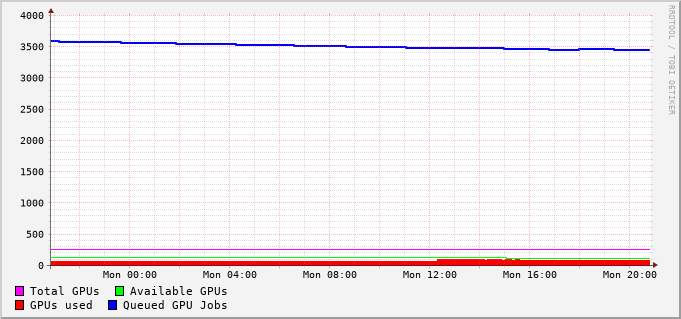
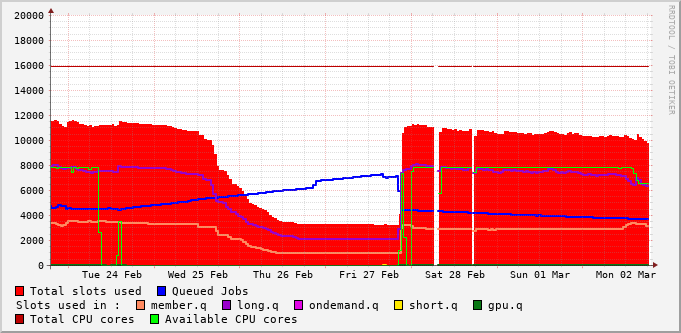
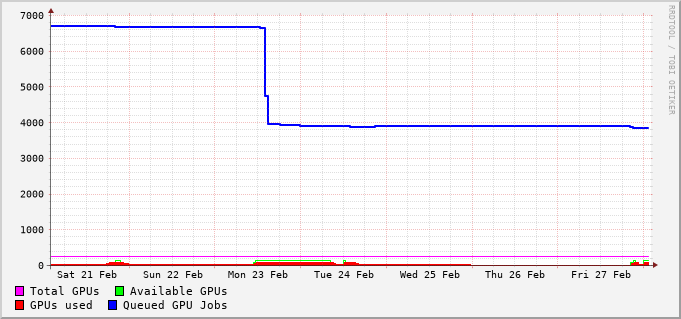
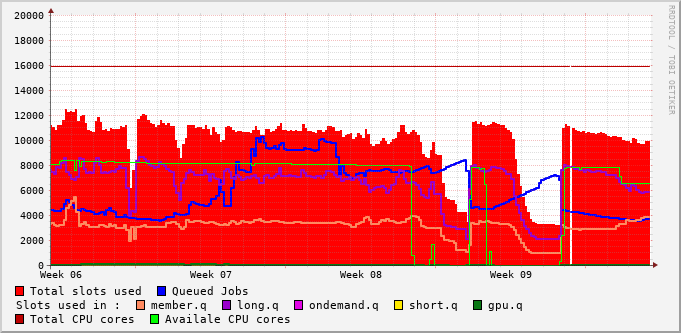
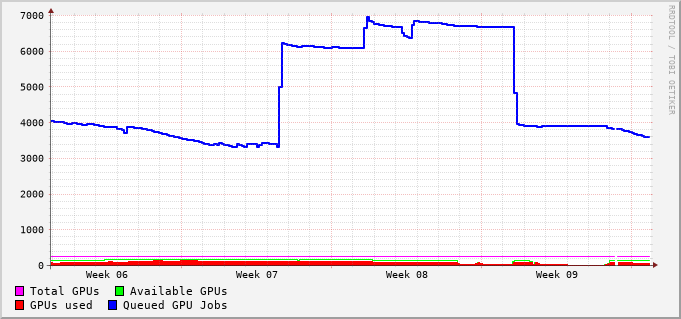
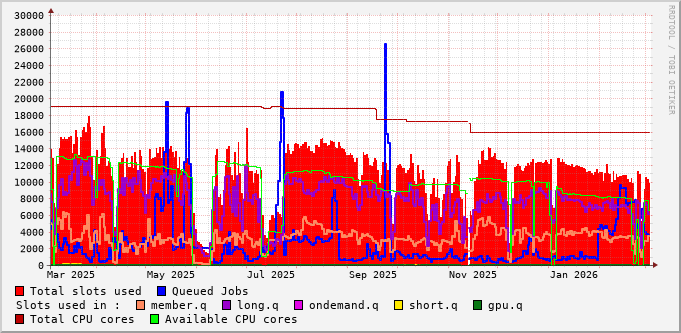
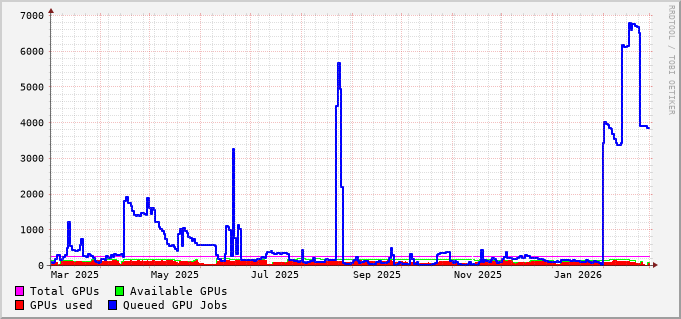
File-System Metrics #
Last known heartbeat: Loading…
Figure: The total, relative processing time on the logarithmic scale for one benchmarking run to complete over time. The values presented are relative to the best case scenario when there is no load, in which case the value is 1.0. The larger the relative time is, the more lag there is on the file system. Annotation of lagginess ranges: 1-2: excellent (light green), 2-5: good (green), 5-20: sluggish (orange), 20-100: bad (red), 100 and above: critical (purple).
Details: These benchmarks are run every ten minutes from different hosts and toward different types of the file system. These metrics are based on a set of commands, part of the wynton-bench tool, that interacts with the file system that is being benchmarked. The relevant ones are: reading a large file from /wynton/home/, copying that large archive file to and from the BeeGFS path being benchmarked, extracting the archive to the path being benchmarked, finding one file among the extracted files, calculating the total file size, and re-archiving and compressing the extracted files. When there’s minimal load on /wynton, the processing time is ~19 seconds. In contrast, when benchmarking local /scratch, the total processing time is about three seconds.
When BeeGFS struggles to keep up with metadata and storage requests, the BeeGFS lagginess goes up. We can use beegfs-ctl --serverstats --perserver --nodetype=meta and beegfs-ctl --serverstats --perserver --nodetype=storage to see the amount of BeeGFS operations that are queued up (qlen) per metadata and storage server. When things run smoothly, the queue lengths should be near zero (qlen less than ten). When BeeGFS struggles to keep up, we typically find large qlen values for one or more servers. To see if the BeeGFS load is high due to file storage or metadata I/O performed by specific users, we can use beegfs-ctl --userstats .... For example, beegfs-ctl --userstats --names --interval=10 --maxlines=5 --nodetype=storage summarizes storage operations every ten seconds and list the five users with the most operations. Similarly, beegfs-ctl --userstats --names --interval=10 --maxlines=5 --nodetype=meta shows metadata operations per user.
Miscellaneous Metrics #
Detailed statistics on the file-system load and other cluster metrics can be found on the Wynton HPC Grafana Dashboard. To access this, make sure you are on the UCSF network. Use your Wynton HPC credential to log in.
Compute Nodes #
Upcoming Incidents #
None.
Current Incidents #
November 16, 2023-ongoing #
Sporadic job failure #
Update: There was another burst of “can’t get password entry for
user” errors starting on 2025-01-26 around 15:30, causing jobs to fail
immediately. We are restarting the SSSD service on the ~140 compute
nodes we have identified as suffering from this problem.
Update: To lower the risk for this problem to occur, the SSSD
timeout limit was increased from 10 seconds to 30 seconds.
Update: The “can’t get password entry for user” error happens on
some compute nodes where the System Security Services Daemon (SSSD)
has failed. Until the cause for failed SSSD has been identified and
resolved, the only solution is to resubmit the job.
Notice: Some jobs end up in an error state (Eqw) with an error
“can’t get password entry for user “alice”. Either user does not exist
or error with NIS/LDAP etc.”
November 5, 2023-ongoing #
Passwords cannot be reset #
Notice: Passwords can be changed via the web interface. It is
still not possible to change it via the command-line while logged in
to Wynton.
Notice: It is not possible to change or reset passwords since
2023-11-05. This problem was introduced while doing cluster-wide
upgrades to Rocky 8.
Past Incidents #
Operational Summary for 2026 (this far) #
-
Full downtime:
- Scheduled: 22.0 hours (= 0.9 days)
- Unscheduled: 69.25 hours (= 2.9 days)
- Total: 118.25 hours (= 4.9 days)
- External factors: 99% of the above downtime, corresponding to 117.0 hours (= 4.9 days), were due to external factors
-
Partial downtime:
- Scheduled: 0.0 hours (= 0.0 days)
- Unscheduled: 39.5 hours (= 1.6 days)
- Total: 39.5 hours (= 1.6 days)
- External factors: 0% of the above downtime, corresponding to 0.0 hours (= 0.0 days), were due to external factors
Scheduled maintenance downtimes #
- Impact: No file access, no compute resources available
- Damage: None
- Occurrences:
- 2026-06-23 – 2026-06-24 (22.0 hours)
- Total downtime: 22.0 hours
Scheduled kernel maintenance #
- Impact: Fewer compute nodes than usual until rebooted
- Damage: None
- Occurrences:
- N/A
Unscheduled downtimes due to power outage #
- Impact: No file access, no compute resources available
- Damage: Running jobs (<= 14 days) failed, file-transfers failed, possible file corruptions
- Occurrences:
- N/A
- Total downtime: 0.0 hours of which 0.0 hours were due to external factors
Unscheduled downtimes due to file-system failures #
- Impact: No file access
- Damage: Running jobs (<= 14 days) may have failed, file-transfers may have failed, cluster not accessible
- Occurrences:
- 2026-01-01 – 2026-01-05 (95.0 hours)
- 2026-01-07 (1.25 hours)
- 2026-01-15 – 2026-01-16 (12.5 hours) [partial]
- 2026-01-25 – 2026-01-27 (27.0 hours) [partial]
- 2026-02-20 – 2026-03-24 (238.75 hours) [partial]
- Total downtime: 374.5 hours of which 95.0 hours were due to external factors
Unscheduled downtimes due to other reasons #
- Impact: Less compute resources
- Damage: Running jobs (<= 14 days) may have failed, file-transfers may have failed, cluster not accessible
- Occurrences:
- N/A
- Total downtime: 0.0 hours of which 0.0 hours were due to external factors
June 23-24, 2026 #
Full downtime #
Resolved: Wynton HPC is available as of June 24 at 6:00 PM. Compute nodes are rebooted with require in-person manual reboot.
Notice: Wynton HPC was shut down on June 23 at 8:00 PM.
Notice: Wynton HPC will undergo a planned maintenance window
beginning Tuesday, June 23 at 8:00 PM through Wednesday, June 24 at
1:00 PM due to a facilities electrical shutdown in Byers Hall. To
prepare for the maintenance, the scheduler has been configured to
prevent jobs from starting if they can’t be completed before the
maintenance window begins. Jobs that cannot complete before the
downtime begins will not be started by the scheduler until after the
downtime is completed. Some running jobs may be interrupted during the
maintenance window.
February 20-March 24, 2026 #
BeeGFS storage outage #
Resolved: All BeeGFS storage servers are now fully functional.
Notice: One pool on BeeGFS storage server bss16 is offline.
Notice: All BeeGFS storage servers are available again.
Notice: BeeGFS storage servers bss15 and bss16 are experiencing
issues again. This affects some users’ group storage resulting in
stalled file access and possible timeouts.
Notice: All BeeGFS storage servers are stable again.
Notice: BeeGFS storage servers bss15 and bss16 are experiencing
issues. This affects some users’ group storage resulting in stalled
file access and possible timeouts.
Notice: Jobs and the job queue have been resumed. The status of
BeeGFS metadata and storage servers is now all okay. We will keep
monitoring the file system as load is ramping up.
Notice: Status quo - all jobs and the job queue remain suspended.
A definitive root cause has not yet been identified. In the meanwhile,
storage drive pairs keep being re-synchronized.
Notice: All jobs and the job queue are suspended. The Wynton Team
is working with support vendors and the UCSF networking team to
troubleshoot.
Notice: Jobs and the job queue have been resumed. The root cause
is still being investigated. There is a risk for subsequential file
system issues resulting in job hanging.
Notice: All jobs and the job queue remain suspended. The Wynton Team
is working on this as a top priority.
Notice: The Wynton Team has been working throughout the weekend to
monitor and mitigate issues with the BeeGFS storage servers.
Notice: All jobs have been paused. They will be automatically
resumed when the file system is stable again.
Notice: BeeGFS is experiencing issues since Friday at 17:55.
January 25-27, 2026 #
Partial BeeGFS storage failure #
Update: One section (bss9) of the BeeGFS file system went offline
since 17:45 on 2026-01-26. It was resolved on 2026-01-27 at 08:15.
Users experiences errors such as “Communication error on send”.
Update: One section (bss16) of the BeeGFS file system went offline
since 20:15 on 2026-01-25. It was resolved on 2026-01-26 at
08:15. Users experiences errors such as “Communication error on send”.
January 15-16, 2026 #
Partial BeeGFS storage failure #
Update: All of the BeeGFS file system is available again.
Notice: One section (bss16) of the BeeGFS file system is offline
since 00:00 on 2026-01-26.
Update: All of the BeeGFS file system is available again.
Notice: Two sections (bss6 and bss16) of the BeeGFS file system
are offline since 06:45-07:00 this morning.
January 7, 2026 #
BeeGFS issue #
Resolved: BeeGFS issues are resolved after rebooting a storage
server. This incidents requires some resynchronization, which will
induce some lagginess until finished.
Notice: BeeGFS experiences issues.
January 1-5, 2026 #
Cluster unavailable #
Resolved: All interactive nodes but pdt1 are available. We
consider the original incident resolved.
Update: Interactive nodes log1, dt1, and plog1 are available
again. Th
Update: The cluster is resumed, except interactive nodes log1,
dt1, plog1, and pdt1.
Update: Wynton jobs are paused until a network switch issue can be
addressed on Monday 2026-01-05. Users can still log in, but will not
be able to run jobs. The cluster will be shut down (no logins) on
Monday morning at 09:00 with a plan to make it available again the
same evening, but the outage may extend through Tuesday afternoon.
Update: The cluster will be sporadically unavailable for extended
periods of time due to ongoing BeeGFS resynchronization.
Update: The cluster is available, except interactive nodes log1,
dt1, and pdt1. Jobs are suspended until BeeGFS resynchronizations
have stabilized.
Notice: The cluster is unavailable since 2026-01-01 15:30. It is
not possible to access the login or the data-transfer nodes. Initial
investigation suggests that network issues caused BeeGFS issues.
Operational Summary for 2025 #
-
Full downtime:
- Scheduled: 27.0 hours (= 1.1 days) = 0.3%
- Unscheduled: 551.25 hours (= 23.0 days) = 6.3%
- Total: 578.25 hours (= 24.1 days) = 6.6%
- External factors: 7.2% of the above downtime, corresponding to 41.5 hours (= 1.7 days), were due to external factors
Scheduled maintenance downtimes #
- Impact: No file access, no compute resources available
- Damage: None
- Occurrences:
- 2025-11-12 – 2025-11-13 (27.0 hours)
- Total downtime: 27.0 hours of which 0.0 hours were due to external factors
Scheduled kernel maintenance #
- Impact: Fewer compute nodes than usual until rebooted
- Damage: None
- Occurrences:
- N/A
Unscheduled downtimes due to power outage #
- Impact: No file access, no compute resources available
- Damage: Running jobs (<= 14 days) failed, file-transfers failed, possible file corruptions
- Occurrences:
- N/A
- Total downtime: 0.0 hours
Unscheduled downtimes due to file-system failures #
- Impact: No file access
- Damage: Running jobs (<= 14 days) may have failed, file-transfers may have failed, cluster not accessible
- Occurrences:
- 2025-01-09 – 2025-01-09 ( 1.25 hours)
- 2025-01-17 – 2025-01-22 (81.75 hours)
- 2025-02-21 – 2025-03-07 (61.0 hours)
- 2025-03-31 – 2025-04-01 (17.0 hours)
- 2025-04-11 – 2025-04-14 (62.0 hours)
- 2025-05-29 – 2025-06-10 (282.0 hours)
- 2025-12-31 – 2025-12-31 ( 4.75 hours)
- Total downtime: 509.75 hours of which 0.0 hours were due to external factors
Unscheduled downtimes due to other reasons #
- Impact: Less compute resources
- Damage: Running jobs (<= 14 days) may have failed, file-transfers may have failed, cluster not accessible
- Occurrences:
- 2025-12-07 – 2025-12-09 (41.5 hours)
- Total downtime: 41.5 hours of which 41.5 hours were due to external factors
December 31, 2025 #
BeeGFS non-responsive #
Resolved: BeeGFS is available again.
Notice: BeeGFS is non-responsive.
December 7-9, 2025 #
Major file system issues #
Resolved: Data-transfer nodes dt1 and pdt1 online.
Update: The cluster is online again. All interactive nodes, except
data-transfer nodes dt1 and pdt1.
Update: The resynchronization of the BeeGFS file servers is almost
completed. We anticipate putting the cluster back online during the
afternoon.
Update: Network switch issues on Sunday evening triggered problems
with the BeeGFS file system. Those BeeGFS issues have now been
addressed. The file servers are now resynchronizing. We will keep
the cluster offline until that has completed, which we estimate to
happen tomorrow.
Notice: Wynton is experiencing issues with the file system and
needs to be shut down for maintenance. All existing jobs have been
paused. No new jobs can be run until further notice. Logins
currently fail. First indications of problems were observed on
2025-12-06 around 19:00.
November 12-13, 2025 #
Full downtime #
Resolved: The BeeGFS meta server pairs resynchronization took around
two days to complete. During this time we experiences several
incidents of extended large BeeGFS lagginess, especially so during the
first 12-24 hours.
Update: The downtime has concluded and the maintenance has been
successfully completed. The cluster is now back up and running. Please
note, you may experience some lag over the next 24 hours as the
file-system metadata servers continue to re-synchronize.
Update: The cluster is down for maintenance.
Notice: The cluster will down for maintenance from 3:00 pm on
Wednesday November 12 until 6:00 pm on Thursday November 13, 2025.
This is a full downtime, including no access to login, development,
data-transfer, and app nodes. Compute nodes will be shutdown as
well. Jobs with runtimes that go into the maintenance window will be
started after the downtime. Starting October 29 at 4:00pm, jobs
relying on the default 14-day runtime will not be launched until after
the downtime. UCSF Facilities will perform annual fire inspection
activities to remain compliant with regulations. The network team will
update a core switch. The Wynton team will take the opportunity to
implement kernel updates during this period.
May 29-June 10, 2025 #
Major file system failures #
Resolved: Wynton logins are available as of noon today. At that time
we will start unsuspending jobs. We lost about 50 TiBs (0.7%) of
compressed data from 6550 TiBs with the group storage pool for files
in /wynton/group, /wynton/protected/group, and
/wynton/protected/project. See Wynton Announcement email for further
details.
Update: We plan to resume operations by the weekend, given that
the current backup and the necessary, manual one-at-the-time
replacement of multiple drives completes in time. Files that lived on
the failed storage pool are broken and cannot not be fully read, but
possible partially. Home directories are unaffected. The affected
files live under /wynton/group, /wynton/protected/group, and
/wynton/protected/project. We are scanning the file system to
identify exactly which files are affected - this is a slow
processes. We will share file lists with affected groups. Eventually,
any broken files have to be deleted.
Update: Wynton jobs and logins are still paused until further
notice. Our team is working on determining all of the files that may
be corrupt/unavailable and will work with the vendor on the best
course of action. We do not yet have an estimate on when we will be
back up.
Notice: Jobs and logins have been paused until further notice.
Our team is actively troubleshooting and coordinating with the vendor.
A drive was replaced today and was in the process of resilvering when
two more drives failed, totally three failed drives, which causes
significant problems. Data corruption is expected.
April 11-14, 2025 #
File system timeouts #
Resolved: All cluster jobs and queues were unsuspended at 02:00
this night.
Notice: All cluster jobs have been suspended in order to allow
multiple metadata mirror resyncing processes to complete. These
processes are what led to the hanging episodes that we have been
seeing. Interactive nodes remain available. Resyncing processes are
estimated to complete by Monday.
March 31-April 1, 2025 #
File system timeouts #
Resolved: Queues and jobs are re-enabled.
Update: Login is re-enabled. Queues and jobs remains suspended.
Notice: BeeGFS metadata servers are experiencing issues. We have
suspended all queues and jobs and disabled logins. We will work with
the file system vendor to resolve the issue.
February 21-March 7, 2025 #
File system timeouts #
Resolved: We have resumed the scheduler and jobs are being
processed again. We identified several problems related to the BeeGFS
file system that could have contributed to the recent, severe
performance degradation. Specifically, the process that automatically
removes files older than 14 days from /wynton/scratch/ failed to
complete, which resulted in close to 100% full storage servers. We
believe this issues started in November 2024 and has gone unnoticed
until now. We do not understand why these cleanup processes had
failed, but one hypothesis is that there are corrupt files or folders
where the cleanup process gets stuck, preventing it from cleaning up
elsewhere. It might be that these problems have caused our metadata
servers resynchronizing over and over - resynchronization itself is an
indication that something is wrong. We are in the process of
robustifying our cleanup process, putting in monitoring systems to
detect these issues before system degradation takes place.
Notice: We have decided to again suspending all running jobs and
disable the queue from taking on new jobs.
Notice: Resynchronization of BeeGFS metadata server pair (42,52)
finished after 23 hours.
Notice: Resynchronization of BeeGFS metadata server pairs (32,22)
and (23,33) started 2025-03-03, and (42,52) on 2025-03-04.
Notice: The job queue has been re-enabled and all suspended jobs
have been released.
Notice: Login and file transfers to Wynton has been re-enabled.
Notice: Resynchronization of BeeGFS metadata server pair (41,51)
completed after 24 hours, and pair (63,73) completed after 18 hours.
Notice: In order to speed up resynchronization of metadata
servers, we have decided to minimize the load on the file system by
suspending all running jobs, disable login to Wynton, and disable all
file transfers to and from Wynton.
Notice: The file system latency is extremely high, resulting in
the cluster being unusable and attempts to log in via SSH
failing. This is due to the resynchronization of BeeGFS metadata
server pair (51,73).
Notice: Resynchronization of BeeGFS metadata server pair
meta22 and meta32 completed after 30 hours.
Notice: The file system latency is extremely high, resulting in
the cluster being unusable and attempts to log in via SSH
failing. This is due to the resynchronization of BeeGFS metadata
server pair (22,32).
Notice: We are working with the vendor to try to resolve this
problem.
Notice: The file system is again very slow.
delays when working interactively and jobs to slow down.
Notice: The file system is again very slow.
Notice: The file system is very slow, which result in long delays
when working interactively and jobs to take longer than usual.
February 21-24, 2025 #
Kernel maintenance #
Resolved: Login node plog1 respects SSH keys again.
Update: Login node plog1 is available again, but does not respect
SSH keys.
Update: Data-transfer node dt1 is available again.
Update: With the exception for plog1 and dt1, all login,
data-transfer, and development nodes have been rebooted. Until plog1
is available, PHI-users may use pdt1 and pdt2 to login into the
cluster.
Notice: New operating-system kernels are deployed. Login,
data-transfer, and development nodes will be rebooted on Saturday,
February 22, 2025 at 13:00. Compute nodes will no longer accept new
jobs until they have been rebooted. A node will be rebooted as soon as
any existing jobs have completed, which may take up to two weeks
(maximum runtime). During this update period, there will be fewer than
usual slots available on the queues.
February 22-24, 2025 #
Globus issues #
Resolved: The ‘Wynton HPC’ Globus endpoint used by non-PHI users
is available again after data-transfer node dt1 coming online.
Notice: The ‘Wynton HPC’ Globus endpoint used by non-PHI users is
unavailable, because data-transfer node dt1 is unavailable.
February 18-24, 2025 #
Globus issues #
Resolved: The ‘Wynton HPC UCSF Box Connector’ for Globus and the
‘Wynton HPC PHI Compatible’ Globus endpoint are functional again.
Update: The vendor has escalated our support ticket.
Notice: The ‘Wynton HPC UCSF Box Connector’ for Globus and the
‘Wynton HPC PHI Compatible’ Globus endpoint are currently
unavailable. The former gives an error on “Unknown user or wrong
password”, and the latter “Authentication Required - Identity set
contains an identity from an allowed domain, but it does not map to a
valid username for this connector”. The regular ‘Wynton HPC’ Globus
endpoint is unaffected and available. The problem has been there since
at least 2025-02-14 at 22:36, when I user reported it.
January 17-22, 2025 #
Cluster unavailable #
Resolved: Wynton is fully operational again. The BeeGFS file
system issue has been resolved. All data consistency has been
verified. Working with the vendor, we have identified a potential bug
in the BeeGFS quota system that caused the BeeGFS outage. That part is
still under investigation in order to minimize and remove the risk of
reoccurrence.
Update: The login and data-transfer nodes are available again.
Update: The third resynchronization completed successfully.
Update: Further investigation of the failed resynchronization this
morning indicated that the resynchronization did indeed keep running
while it stopped producing any output and the underlying BeeGFS
service was unresponsive. Because of this, we decided to not restart
the resynchronization, but instead let it continue in the hope it will
finish. But, by not restarting, Wynton will remain inaccessible. Our
first objective is to not jeopardize the cluster, the second objective
is to bring the system back online.
Update: The cluster is unavailable again. The past
resynchronization of the problematic BeeGFS metadata server failed
again, which triggers the problem. We are communicating with the
vendor for their support.
Update: The cluster is available again, but the scheduler has been
paused. No queued jobs are launched and running jobs have been
suspended, but will resume when the pause of scheduler is
removed. This is done to minimize the load on BeeGFS, which will
simplify troubleshooting and increase the chances to stabilize
BeeGFS. It is the same BeeGFS metadata server as before that is
experiencing problems.
Update: The cluster is unavailable again.
Update: The cluster is working again. We have started a
resynchronization of the problematic BeeGFS metadata server pair
meta22 and meta32.
Update: First signs of the cluster coming back online again,
e.g. queued jobs are launched, and it is possible to access the
cluster via SSH.
Update: Identifies a specific BeeGFS metadata server that is
unresponsive. The BeeGFS vendor has been contacted.
Update: The underlying problem appears to be BeeGFS. The storage
servers are okay, but one or more metadata servers are unresponsive.
Notice: The cluster is unavailable, e.g. it is not possible to
access the login or the data-transfer nodes.
January 9, 2025 #
File-system emergency shutdown #
Resolved: The cluster full operational again. Suspended jobs have
been resumed. The BeeGFS issue has been resolved. Checked hardware and
cables. Rebooted affected BeeGFS server.
Notice: An issue with BeeGFS was detected. All Wynton jobs have
been paused until further notice.
Operational Summary for 2024 #
-
Full downtime:
- Scheduled: 137.0 hours (= 5.7 days) = 1.6%
- Unscheduled: 142.3 hours (= 5.9 days) = 1.6%
- Total: 279.3 hours (= 11.6 days) = 3.2%
- External factors: 0% of the above downtime, corresponding to 0.0 hours (= 0.0 days), were due to external factors
Scheduled maintenance downtimes #
- Impact: No file access, no compute resources available
- Damage: None
- Occurrences:
- 2024-06-17 – 2024-06-18 (32.0 hours)
- 2024-10-14 – 2024-10-18 (105.0 hours)
- Total downtime: 137.0 hours
Scheduled kernel maintenance #
- Impact: Fewer compute nodes than usual until rebooted
- Damage: None
- Occurrences:
- 2024-04-03 (~500 hours)
Unscheduled downtimes due to power outage #
- Impact: No file access, no compute resources available
- Damage: Running jobs (<= 14 days) failed, file-transfers failed, possible file corruptions
- Occurrences:
- N/A
- Total downtime: 0.0 hours of which 0.0 hours were due to external factors
Unscheduled downtimes due to file-system failures #
- Impact: No file access
- Damage: Running jobs (<= 14 days) may have failed, file-transfers may have failed, cluster not accessible
- Occurrences:
- 2024-03-14 (13.0 hours)
- 2024-03-17 (15.0 hours)
- 2024-05-31 (2.3 hours)
- 2024-06-15 – 2024-06-21 (112.0 hours; excluding 32 hours scheduled maintenance)
- Total downtime: 142.3 hours of which 0.0 hours were due to external factors
Unscheduled downtimes due to other reasons #
- Impact: Less compute resources
- Damage: Running jobs (<= 14 days) may have failed, file-transfers may have failed, cluster not accessible
- Occurrences:
- N/A
- Total downtime: 0.0 hours of which 0.0 hours were due to external factors
October 14-18, 2024 #
Full downtime #
Resolved: The cluster is back online.
Update: The cluster including all its storage is offline
undergoing a scheduled maintenance.
Notice: The cluster will be shut down for maintenance from 8:00 am
on Monday October 14 until 5:00 pm on Friday October 18, 2024. This is
a full downtime, including no access to login, development,
data-transfer, and app nodes. Compute nodes will be shutdown as
well. Starting 14 days before, the maximum job runtime will be
decreased on a daily basis from the current 14 days down to one day so
that jobs finish in time before the shutdown. Jobs with runtimes that
go into the maintenance window will be started after the downtime.
The reason for the downtime is that UCSF Facilities will perform
maintenance affecting cooling in our data center. We will take this
opportunity to perform system updates and BeeGFS maintenance.
September 12, 2024 #
Kernel maintenance #
Resolved: All interactive nodes have been updated and deployed with the new CGroups limits.
Notice: All interactive nodes will be shutdown and rebooted on Thursday September 12 at 12:30 to update Linux kernels and deploy CGroups-controlled CPU and memory user limits. To avoid data loss, please save your work and logout before. Queued and running jobs are not affected.
June 15-25, 2024 #
File-system unreliable #
Resolved: 14,000 compute slots are now available, which
corresponds to the majority of compute nodes.
Update: We will go ahead and re-enable the remaining compute
nodes.
Update: Development nodes are available. We have also opened up
100 compute nodes. We will keep monitoring BeeGFS over the weekend
with the plan to re-enable the remaining compute nodes if all go well.
Update: The login and data-transfer nodes are available. We will
continue to validate BeeGFS during the day with the intent to open up
the development nodes and a portion of the compute nodes before the
weekend.
Update: We decided to replace the problematic chassis with a
spare. The RAID file system has two failing drives, which are
currently being restored. We expect this to finish up in the
morning. Then, we will replace those two failing drives and proceed
with another restore. If that succeeds, we plan to open up the login
nodes to make files available again. After that, the goal is to slowly
open up the queue and compute nodes over the weekend.
Update: We had folks onsite today to complete some preventative
maintenance on all of the disk chassis (and, in a fit of optimism,
bring up all of the nodes to prepare for a return to production). As
this maintenance involved new firmware, we had some hope that it might
sort out our issues with the problematic chassis. Unfortunately, our
testing was still able to cause an issue (read: crash). We’ve sent
details from this latest crash to the vendor and we’ll be pushing hard
to work with them tomorrow Thursday to sort things out.
Update: The vendor is still working on diagnosing our disk chassis
issue. That work will resume after Wednesday’s holiday. So,
unfortunately, we will not be able to bring Wynton up on Wednesday.
We hope to come up on Thursday, but it all depends on our testing and
the vendor’s investigation.
Update: We are working with both the system and chassis vendors to
diagnose this and determine what the problem is and how to fix
it. This process is taking much longer than we’d like, and it is
looking increasingly unlikely that we’ll be in a position to bring
Wynton back online today.
Update: A disk chassis that hosts part of /wynton/home appears
to be failing. It works for a while and then fails, which brings down
/wynton. We are trying to keep it running as much as possible, but
can’t make any promises.
Notice: Wynton is currently down due to an unknown issue. The
problem started around 15:00 on Saturday 2024-06-15.
June 17-18, 2024 #
Full downtime #
Update: All but one of the planned maintenance upgrades were
completed during this scheduled maintenance. The remain upgrade does
not require a downtime and will be done in a near future without
disrupting the cluster.
Update: Wynton is down for maintenance as of 09:00 on Monday
2024-06-17.
Notice: The cluster will be shut down for maintenance from 9 pm on Monday June 17 until 5:00 pm on Tuesday June 18, 2024. Starting June 3, the maximum job runtime will be decreased on a daily basis from the current 14 days so that jobs finish in time. Jobs with runtimes going into the maintenance window, will be started after the downtime.
June 7-June 10, 2024 #
Development nodes are inaccessible #
Resolved: Development nodes are available again.
Notice: Development nodes are inaccessible since Friday June 7
at 17:00. We will investigate the problem on Monday.
May 31, 2024 #
File-system failures #
Resolved: The BeeGFS issue has been resolved. Wynton is
operational again.
Notice: Wynton is currently down due to an unknown issue with the
BeeGFS filesystem. The problem started around 06:00. We’re working on
it and will post updates as we know more.
April 3-25, 2024 #
Kernel maintenance #
Resolved: All compute nodes have been rebooted.
Update: Login, data-transfer, and development nodes have been rebooted.
Update: A new set of kernel updates will be rolled out. Login, data-transfer, and development nodes will be rebooted briefly on Thursday April 11 at 11:00. All compute nodes will also have to be drained and rebooted, which might take up to two weeks. Some of the compute have been draining since last week, meaning that will only have been drain for at most another week.
Update: Hosts dt1 and plog1 are now also available.
Update: Login, data-transfer, and development nodes have been rebooted. It will take some more time before dt1 and plog1 are available again, because they did not come back as expected after the reboot.
Notice: New operating-system kernels are deployed. Login, data-transfer, and development nodes will be rebooted on Thursday April 4 at 11:00. Compute nodes will no longer accept new jobs until they have been rebooted. A node will be rebooted as soon as any existing jobs have completed, which may take up to two weeks (maximum runtime). During this update period, there will be fewer than usual slots available on the queues.
March 17-18, 2024 #
File-system failures #
Resolved: Wynton and BeeGFS is back up and running again after a
full reboot of the BeeGFS servers. Root cause is still unknown.
Notice: Wynton is currently down due to an unknown BeeGFS
issues. The problem started around 19:30 on 2024-03-17. We’re working
on it and will post updates as we know more.
March 14, 2024 #
File-system failures #
Resolved: Wynton and BeeGFS is back up and running again after a
full reboot of the BeeGFS servers. Root cause is still unknown.
Notice: Wynton is currently down due to an unknown issue with the
BeeGFS filesystem. The problem started at 02:11 this morning. We’re
working on it and will post updates as we know more.
February 2-3, 2024 #
Kernel maintenance #
Resolved: All hosts are available.
Update: Login, data-transfer, and development nodes have been
rebooted. It will take some more time before plog1, dt1, and
dev2 are available again, because they did not come back as expected
after the reboot. PHI users may use pdt1 and pdt2 to access the
cluster.
Notice: New operating-system kernels are deployed. Login,
data-transfer, and development nodes will be rebooted on Friday
February 2 at 14:00. Compute nodes will no longer accept new jobs until
they have been rebooted. A node will be rebooted as soon as any
existing jobs have completed, which may take up to two weeks (maximum
runtime). During this update period, there will be fewer than usual
slots available on the queues.
January 25-August, 2024 #
Emergency shutdown due to cooling issue #
Resolved: UCSF Facilities has resolved the cooling issue and there
are again two working chillers. As a fallback backup, the building is
now connected to the campus chilled water loop. This was confirmed by
UCSF Facilities on 2024-12-10.
Update: UCSF Facilities performed testing for rerouting of updated
chilled-water piping the building where the Wynton data center is
hosted between 07-12 on 2024-05-08.
Update: The compute and development nodes are available again.
Jobs that were running when we did the emergency shutdown should be
considered lost and need to be resubmitted. UCSF Facilities has
re-established cooling, but there is currently no redundancy cooling
system available, meaning there is a higher-than-usual risk for
another failure.
Notice: We are shutting down all Wynton compute and development
nodes as an emergency action. This is due to a serious issue with the
chilled-water system that feeds the cooling in the Wynton data
center. By shutting down all of the compute nodes, we hope to slow the
current temperature rise, while keeping the storage system, login and
data-transfer nodes up. The will come back up again as soon as the
UCSF Facilities has resolved the chilled-water system. ETA is
currently unknown.
Operational Summary for 2023 #
- Full downtime:
- Scheduled: 141.0 hours = 5.9 days = 1.6%
- Unscheduled: 742.25 hours = 30.9 days = 8.5%
- Total: 883.25 hours = 35.3 days = 10.1%
- External factors: 0% of the above downtime, corresponding to 0.0 hours (= 0.0 days), were due to external factors
Scheduled maintenance downtimes #
- Impact: No file access, no compute resources available
- Damage: None
- Occurrences:
- 2023-02-22 (17.0 hours)
- 2023-05-17 (20.0 hours)
- 2023-10-30 – 2023-11-03 (104.0 hours)
- Total downtime: 141.0 hours
Scheduled kernel maintenance #
- Impact: Fewer compute nodes than usual until rebooted
- Damage: None
- Occurrences:
- N/A
Unscheduled downtimes due to power outage #
- Impact: No file access, no compute resources available
- Damage: Running jobs (<= 14 days) failed, file-transfers failed, possible file corruptions
- Occurrences:
- N/A
- Total downtime: 0.0 hours of which 0.0 hours were due to external factors
Unscheduled downtimes due to file-system failures #
- Impact: No file access
- Damage: Running jobs (<= 14 days) may have failed, file-transfers may have failed, cluster not accessible
- Occurrences:
- 2023-05-17 – 2023-06-01 (359.0 hours)
- 2023-10-27 – 2023-11-15 (347.25 hours, excluding the scheduled 5-day downtime)
- Total downtime: 742.25 hours of which 0.0 hours were due to external factors
Unscheduled downtimes due to other reasons #
- Impact: Less compute resources
- Damage: Running jobs (<= 14 days) may have failed, file-transfers may have failed, cluster not accessible
- Occurrences:
- N/A
- Total downtime: 0.0 hours of which 0.0 hours were due to external factors
November 15-December 15, 2023 #
Upgrading compute nodes #
Resolved: All compute nodes are up and running.
Update: A total of ~15,000 CPU cores are now up and running.
Update: A total of ~14,000 CPU cores are now up and running.
Update: A total of ~13,000 CPU cores are now up and running.
Update: A total of ~12,000 CPU cores are now up and running.
Update: A total of ~10,000 CPU cores are now up and running.
Update: 98 compute nodes with a total of 2,780 CPU cores are now
up and running.
Notice: As we come back from the downtime, we start out with 36
out of 490 compute nodes available to process jobs. Work continues to
migrating the remaining nodes to Rocky 8.
October 30-November 15, 2023 #
Full downtime #
Update: The job scheduler is available and jobs are running. The
data-transfer nodes are available. At this time, 36 out of 490 compute
nodes have been re-enabled. Work has begun booting up the remaining
ones. The first jobs were processed around 09:00 this morning.
Update: We plan to re-enable the job scheduler and start
processing jobs by the end of today. It is possible to submit jobs
already now, but they will remain queued until we re-enable the
scheduler.
Update: The BeeGFS issue has been resolved, which allows us to
move forward on the remaining Rocky-8 updates. We hope to start
bringing compute nodes online as soon as tomorrow (2023-11-15).
Update: Still status quo; the BeeGFS issue holds us back from
bringing the scheduler back up. We’re rather certain that we will not
be able to resolve it today or tomorrow.
Update: Login and development nodes are available. Write access to
the BeeGFS file system has been re-enabled. Due to continued issues in
getting BeeGFS back in stable state, we are still not ready for
opening up the scheduler and compute nodes.
Update: Unfortunately, we will not bring up Wynton to run jobs
today. We are evaluating what, if anything, may be possible to bring
up before the long weekend. The reason being that the required
metadata resynchronization failed late yesterday. The vendor has
provided us with a script to fix the failure. That script is running,
and once it’s done, we’ll reattempt to resynchronize.
Update: We estimate to bring Wynton back up by the end of day
Thursday November 9, 2023. At that time, we expect all login, all
data-transfer, and most development nodes will be available. A large
number of the compute nodes will also be available via the scheduler.
Update: The team makes progress on the scheduled downtime
activities, which was delayed due to the BeeGFS incident. We estimate
to bring Wynton back up by the end of day Thursday November 9, 2023.
Notice: The cluster will be shut down for maintenance from 9 pm on
Monday October 30 through end of business on Friday November 3, 2023
(2023W44). The operating system will be upgraded system wide (all
machines) from CentOS 7.9 to Rocky 8 Linux, the BeeGFS will be
upgrade, and old hardware will be replaced. UCSF Facilities will
perform scheduled work. After the downtime, there will no longer be
any machine running CentOS 7.9. All machines will have their local
disks (including /scratch and /tmp) wiped. Anything under
/wynton (including /wynton/scratch, /wynton/home, …) should be
unaffected, but please note that Wynton does not back anything up, so
we recommend you to back up critical data. For more information about
the Rocky 8 Linux migration project and how you can prepare for it is
available at on the Migration to Rocky 8 Linux from CentOS
7 page.
October 27-November 14, 2023 #
File-system failures #
Resolved: The BeeGFS metadata resynchronization is complete around
02:30 this morning.
Update: The BeeGFS metadata resynchronization is still
unresolved. We are looking into other strategies, which we are
currently testing. If those tests are successful, we will attempt to
deploy the fix in the production.
Update: After resynchronization of the BeeGFS metadata kept
failing, we identified a possible culprit. We suspect BeeGFS cannot
handle the folders with many millions of files, causing the
resynchronization to fail. We keep working on stabilizing BeeGFS.
Update: The BeeGFS metadata resynchronization that had been
running for several hours, failed late yesterday. The vendor has
provided us with a script tailored to fix the issue we ran into. That
script is running, and once it’s done, we’ll start the
resynchronization again.
Update: The recovery from the BeeGFS incident goes as planned. We
estimate to have resolved this issue by the end of November 9, 2023,
when full read-write access to /wynton will be available again.
Update: The Wynton team works on fixing and stabilizing the BeeGFS
incident. We estimate to have resolved this issue by the end of
November 9, 2023.
Update: Read-only access to Wynton has been enabled for users to
retrieve their files. Login nodes log1 and plog1 are available for
this. If going through the Wynton 2FA, make sure to answer “no”
(default) when prompted for “Remember connection authentication from
98.153.103.186 for 12 hours? [y/N]”; answering “yes” causes the SSH
connection to fail.
Update: Wynton admins can retrieve user files under /wynton/
upon requests until 18:00 today, when the UCSF network will go
down. We are not able to share the PHI data under
/wynton/protected/. Please contact support with all details
including full path of the data to be retrieved.
Update: The BeeGFS issue is related to a CentOS 7-kernel bug in
one of our BeeGFS metadata servers. To minimize the risk of data loss
on the /wynton file system, we took the decision to shut down Wynton
immediately. At the moment, we do not have an estimate on how long it
will take to resolve this problem. It has to be resolved before we
can begin the major upgrade scheduled for 2023W44.
Notice: The BeeGFS file system, which hosts /wynton, is
experiencing unexpected, major issues. Some or all files on /wynton
cannot be accessed, and when attempted, an Communication error on
send error is seen. The problem started around 13:45 on Friday
2023-10-27.
October 23-October 26, 2023 #
Resolve: Login node log2 and data-transfer node dt1 are
available again.
Update: Development node dev2 is available again.
Notice: Access to login node log2, data-transfer nodes dt1,
and development node dev2 will be disabled from Monday-Friday
October 23-27, 2023 (2023W43) to upgrade the operating system to Rocky
8 Linux. They might return sooner. The alternative login node
log1, data-transfer nodes dt2, and development nodes dev1 and
dev3 are unaffected, so are the Wynton HPC Globus endpoints.
October 16-October 20, 2023 #
Resolved: Login node log1, data-transfer nodes dt2 and pdt2
are available again and are now running Rocky 8.
Notice: Data-transfer nodes dt2 will be disabled this week
instead of dt1 as previously announced.
Notice: Access to login node log1, data-transfer nodes dt1,
and pdt2 will be disabled from Monday-Friday October 16-20, 2023
(2023W42) to upgrade the operating system to Rocky 8 Linux. They
might return sooner. The alternative login node log2, data-transfer
nodes dt2, and pdt1 are unaffected, so are the Wynton HPC Globus
endpoints.
June 1, 2023 - April 3, 2024 #
Post file-system failure incidents #
Resolved: All corrupted and orphaned files have now been deleted. There might be orphaned directories remaining, which we leave to each user to remove, if they exist.
Update: Reading files whose data was lost on the unrecovered storage targets back in May no longer results in an error message. Instead, the portion of the file that was lost will be replaced by null bytes. Obviously, this results in a file with corrupt content. The admins will be going through and deleting all the corrupted files as soon as possible. It’s a big task and will take some time.
Update: The remaining two ZFS storage targets (22004 and 22006) are back online again.
Update: Four out of the six ZFS storage targets have been brought back online. Two targets (22004 and 22006) remain offline. If you encounter a “Communication error on send” error, please do not delete or move the affected file.
Update: Six ZFS storage targets (22001-22006) are down, because one of the recovered storage targets encountered latent damage that had gone undetected since the recovery in May. This locked up the server and thus all six targets on that server.
Update: The final two ZFS storage targets are now serving the BeeGFS file system (/wynton) again.
Update: We will be reintroducing the final two ZFS storage targets back into the BeeGFS file system (/wynton) on Friday June 30. The work will start at 10 am and should take an hour or so. During that time, there will be a couple of brief “blips” as we reconfigure the storage.
Update: Organizing the data recovered from ZFS storage target 22004 into a form suitable for BeeGFS is taking long than expected. Thus far, we’ve properly replaced 10,354,873 of the 11,351,926 recovered files. Approximately one million files remain. We now hope to complete the work this week. The automatic clean up of old files on /wynton/scratch and /wynton/protected/scratch have been resumed.
Update: There are two broken ZFS storage targets (22004 and 21002). We expect to recover most files on target 22004 (approximately 14 TB). The reason it takes this long to recover that storage target is that the file chunks are there, but we have to puzzle them together to reconstruct the original files, which is a slow process. We estimate this process to complete by the end of the week. The files on the other target, target 21002, are unfortunately not recoverable. If you encounter a “Communication error on send” error, please do not delete or move the affected file.
Notice: There are two ZFS storage targets that are still failing and offline. We have hopes to be able to recover files from one of them. As of June 9, about 12 TB of low-level, raw file data (out of ~15 TB) was recovered. When that is completed, we will start the tedious work on reconstructing the actual files lost. The consultants are less optimistic about recovering data from second storage target, because it was much more damaged. They will give us the final verdict by the end of the week. If you encounter a “Communication error on send” error, please do not delete or move the affected file.
May 16-June 1, 2023 #
Full downtime followed by network and file-system recovery #
Resolved: The job scheduler is now available. Access to /wynton/group, /wynton/protected/group, and /wynton/protected/project has been restored. If you encounter a “Communication error on send” error, please do not delete or move the affected file.
Update: Wynton will be fully available later today, meaning the job scheduler and access to /wynton/group, /wynton/protected/group, and /wynton/protected/project will be re-enabled. Note, two ZFS storage targets are still faulty and offline, but the work of trying to recover them will continue while we go live. This means that any files on the above re-opened /wynton subfolders that are stored, in part or in full, on those two offline storage targets will be inaccessible. Any attempt to read such files will result in a “Communication error on send” error and stall. To exit, press Ctrl-C. Importantly, do not attempt to remove, move, or update such files! That will make it impossible to recover them!
Update: In total 22 (92%) out of 24 failed storage targets has been recovered. The consultant hopes to recover the bulk of the data from one of the two remaining damaged targets. The final damage target is heavily damaged, work on it will continue a few more days, but it is likely it cannot be recovered. The plan is to open up /wynton/group tomorrow Thursday with instructions what to expect for files on the damaged targets. The compute nodes and the job scheduler will also be enabled during the day tomorrow.
Update: In total 22 (92%) out of 24 failed storage targets has been recovered. The remaining two targets are unlikely to be fully recovered. We’re hoping to restore the bulk of the files from them, but there is a risk that we will get none back. Then plan is to bring back /wynton/group, /wynton/protected/group, and /wynton/protected/project, and re-enable the job queue, on Thursday.
Update: The login, data-transfer, and development nodes (except gpudev1) are now online an available for use. The job scheduler and compute nodes are kept offline, to allow for continued recovery of the failed ZFS storage pools. For the same reason, folders under /wynton/group, /wynton/protected/group, and /wynton/protected/project are locked down, except for groups who have mirrored storage. /wynton/home and /wynton/scratch are fully available. We have suspended the automatic cleanup of old files under /wynton/scratch and /wynton/protected/scratch. The ZFS consultant recovered 3 of the 6 remaining storage targets. We have now recovered in total 21 (88%) out of 24 failed targets. The recovery work will continue on Monday (sic!).
Update: All 12 ZFS storage targets on one server pair have been recovered and are undergoing final verification, after which that server pair is back in production. On the remaining server pair with also 12 failed ZFS storage targets, 4 targets have been recovered, 4 possibly have been, and 4 are holding out. We’re continuing our work with the consultant on those targets. These storage servers were installed on 2023-03-28, so it is only files written after that date that may be affected. We are tentatively planning on bringing up the login, data transfer and development nodes tomorrow Friday, prior to the long weekend, but access to directories in /wynton/group, /wynton/protected/group, or /wynton/protected/project will be blocked with the exception for a few groups with mirrored storage. /wynton/home and /wynton/scratch would be fully accessible.
Update: 8 more ZFS storage targets were recovered today. We have now recovered in total 17 (71%) out of 24 failed targets. The content of the recovered targets is now being verified. We will continue working with the consultant tomorrow on the remaining 7 storage targets.
Update: The maintenance and upgrade of the Wynton network switch was successful and is now completed. We also made progress of recovering the failed ZFS storage targets - 9 (38%) out of 24 failed targets have been recovered. To maximize our chances at a full recovery, Wynton will be kept down until the consultant completes their initial assessment. Details: The contracted ZFS consultant started to work on recovering the failed ZFS storage targets that we have on four servers. During the two hours of work, they quickly recovered another three targets on on the first server, leaving us with only one failed target on that server. Attempts of the same recovery method on the second and third servers were not successful. There was no time today to work on the fourth server. The work to recover the remaining targets will resume tomorrow. After the initial recovery attempt has been attempted on all targets, the consultant, who is one of the lead ZFS developers, plans to load a development version of ZFS on the servers in order to perform more thorough and deep-reaching recovery attempts.
Update: Wynton will be kept down until the ZFS-recovery consultant has completed their initial assessment. If they get everything back quickly, Wynton will come back up swiftly. If recovery takes longer, or is less certain, we will look at coming back up without the problematic storage targets. As the purchase is being finalized, we hope that the consultant can start their work either on Tuesday or Wednesday. The UCSF Networking Team is performing more maintenance on the switch tonight.
Update: The cluster will be kept offline until at least Tuesday May 23. The BeeGFS file-system failure is because 24 out of 144 ZFS storage targets got corrupted. These 24 storage targets served our “group” storage, which means only files written to /wynton/group, /wynton/protected/group, and /wynton/protected/project within the past couple of months are affected. Files under /wynton/home and /wynton/scratch are not affected. We are scanning the BeeGFS file system to identify exactly which files are affected. Thus far, we have managed to recover 6 (25%) out of the 24 failed targets. The remaining 18 targets are more complicated and we are working with a vendor to start helping us recover them next week.
Update: Automatic cleanup of /wynton/scratch has been disabled.
Update: Several ZFS storage targets that are used by BeeGFS experienced failures during the scheduled maintenance window. There is a very high risk of partial data loss, but we will do everything possible to minimize the loss. In addition, the Wynton core network switch failed and needs to be replaced. The UCSF IT Infrastructure Network Services Team works with the vendor to get a rapid replacement.
Update: The cluster is down and unavailable because of maintenance.
Update: There will be a one-day downtime starting at 21:00 on Tuesday May 16 and ending at 17:00 on Wednesday May 17. This is aligned with a planned PG&E power-outage maintenance on May 17. Starting May 2, the maximum job runtime will be decreased on a daily basis from the maximum 14 days so that jobs finish in time. Jobs with runtimes going into the maintenance window, will only be started after the downtime. The default run time is 14 days, so make sure to specify qsub -l h_rt=<run-time> ... if you want something shorter.
Update: The updated plan is to only have a 24-hour downtime starting the evening of Tuesday May 16 and end by the end of Wednesday May 17. This is aligned with a planned PG&E power-outage maintenance on May 17.
Update: The updated plan is to have the downtime during the week of May 15, 2023 (2023W20). This is aligned with a planned PG&E power-outage maintenance during the same week.
Notice: We will performing a full-week major update to the cluster during late Spring 2023. Current plan is to do this during either the week of May 8, 2023 (2023W19) or the week of May 15, 2023 (2023W20).
February 22-23, 2023 #
Full downtime #
Resolved: The cluster maintenance has completed and the cluster is now fully operational again.
Update: The cluster has been shut down for maintenance.
Notice: The cluster will be shut down for maintenance from 9 pm on Wednesday February 22 until 5:00 pm on Thursday February 23, 2023. This is done to avoid possible file-system and hardware failures when the UCSF Facilities performs power-system maintenance. During this downtime, we will perform cluster maintenance. Starting February 8, the maximum job runtime will be decreased on a daily basis from the current 14 days so that jobs finish in time. Jobs with runtimes going into the maintenance window, will be started after the downtime.
January 24, 2023 #
No access to login and data-transfer hosts #
Resolve: Network issues has been resolved and access to all login
and data-transfer has been re-established. The problem was physical
(a cable was disconnected).
Notice: There is no access to non-PHI login and data-transfer
hosts (log[1-2], dt[1-2]). We suspect a physical issue (e.g. somebody
kicked a cable), which means we need to send someone onsite to fix the
problem.
January 11, 2023 #
No internet access on development nodes #
Resolved: The network issue for the proxy servers has been fixed.
All development nodes now have working internet access.
Workarounds: Until this issue has been resolved, and depending on
needs, you might try to use a data-transfer node.Some of the software
tools on the development nodes are also available on the data-transfer
nodes, e.g. curl, wget, and git.
Notice: The development nodes have no internet access, because the
network used by out proxy servers is down for unknown reasons.
The problem most likely started on January 10 around 15:45.
Operational Summary for 2022 #
-
Full downtime:
- Scheduled: 94.0 hours = 3.9 days = 1.1%
- Unscheduled: 220.0 hours = 9.2 days = 2.5%
- Total: 314.0 hours = 13.1 days = 3.6%
- External factors: 36% of the above downtime, corresponding to 114 hours (= 4.8 days), were due to external factors
Scheduled maintenance downtimes #
- Impact: No file access, no compute resources available
- Damage: None
- Occurrences:
- 2022-02-08 (53.5 hours)
- 2022-09-27 (40.5 hours)
- Total downtime: 94.0 hours
Scheduled kernel maintenance #
- Impact: Fewer compute nodes than usual until rebooted
- Damage: None
- Occurrences:
- 2022-08-05 (up to 14 days)
Unscheduled downtimes due to power outage #
- Impact: No file access, no compute resources available
- Damage: Running jobs (<= 14 days) failed, file-transfers failed, possible file corruptions
- Occurrences:
- 2022-09-06 (66 hours)
- Total downtime: 66 hours of which 66 hours were due to external factors
Unscheduled downtimes due to file-system failures #
- Impact: No file access
- Damage: Running jobs (<= 14 days) may have failed, file-transfers may have failed, cluster not accessible
- Occurrences:
- 2022-03-28 (1 hours): Major BeeGFS issues
- 2022-03-26 (5 hours): Major BeeGFS issues
- 2022-03-18 (100 hours): Major BeeGFS issues
- Total downtime: 106.0 hours of which 0 hours were due to external factors
Unscheduled downtimes due to other reasons #
- Impact: Less compute resources
- Damage: Running jobs (<= 14 days) may have failed, file-transfers may have failed, cluster not accessible
- Occurrences:
- 2022-03-26 (48 hours): Data-center cooling issues
- Total downtime: 48 hours of which 48 hours were due to external factors
Accounts #
- Number of user account: 1,643 (change: +369 during the year)
November 2, 2022 #
Major BeeGFS issues #
Resolved: The BeeGFS issues have been resolved. At 05:29 this morning, a local file system hosting one of our 12 BeeGFS meta daemons crashed. Normally, BeeGFS detects this and redirects processing to a secondary, backup daemon. In this incident, this failback did not get activated and a manual intervention was needed.
Notice: The BeeGFS file system started to experience issues early morning on Tuesday 2022-11-02. The symptoms are missing files and folders.
November 1, 2022 #
Scheduler not available #
Resolved: The job scheduler is responsive again, but we are not
certain what caused the problem. We will keep monitoring the issue.
Notice: The job scheduler, SGE, does not respond to user requests,
e.g. qstat and qsub. No new jobs can be submitted at this time.
The first reports on problems came in around 09:00 this morning. We
are troubleshooting the problem.
September 27-29, 2022 #
Full downtime #
Resolved: The cluster maintenance has completed and the cluster is now fully operational again.
Update: The cluster has been shut down for maintenance.
Notice: Wynton will be shut down on Tuesday September 27, 2022 at 21:00. We expect the cluster to be back up by the end of the workday on Thursday September 29. This is done to avoid file-system and hardware failures that otherwise may occur when the UCSF Facilities performs maintenance to the power system in Byers Hall. We will take the opportunity to perform cluster maintenance after the completion of the power-system maintenance.
September 6-9, 2022 #
Outage following campus power glitch #
Resolved: As of 09:20 on 2022-09-09, the cluster is back in full operation. The queues are enabled, jobs are running, and the development nodes are accepting logins.
Update: Login and data-transfer nodes are disabled to minimize the risk for file corruption.
Notice: The Wynton system experiencing system-wide issues, including the file system, due to a campus power glitch. To minimize the risk of corrupting the file system, it was decided to shut down the job scheduler and terminate all running jobs. The power outage at Mission Bay campus happened at 15:13. Despite diesel-generated backup power started up momentarily, it was enough to affect some of our servers. The job scheduler will be offline until the impact on Wynton is fully investigated.
August 5-9, 2022 #
Kernel maintenance #
Resolved: All compute nodes have been rebooted.
Notice: New operating-system kernels are deployed. Login, data-transfer, and development nodes will be rebooted on Monday August 8 at 14:00. Compute nodes will no longer accept new jobs until they have been rebooted. A node will be rebooted as soon as any existing jobs have completed, which may take up to two weeks (maximum runtime). During this update period, there will be fewer than usual slots available on the queues. To follow the progress, see the green ‘Available CPU cores’ curve (target ~14,500 cores) in the graph above.
August 4, 2022 #
Software repository maintenance #
Resolved: The Sali lab software module repository is back.
Notice: The Sali lab software module repository is back will be unavailable from around 10:30-11:30 today August 4 for maintenance.
March 28-April 6, 2022 #
Major BeeGFS issues #
Resolved: The patch of the BeeGFS servers were successfully deployed by 14:30 and went without disruptions. As a side effect, rudimentary benchmarking shows that this patch also improves the overall performance. Since the troubleshooting, bug fixing, and testing started on 2022-03-28, we managed to keep the impact of the bugs to a minimum resulting in only one hour of BeeGFS stall.
Update: The BeeGFS servers will be updated tomorrow April 6 at 14:00. The cluster should work as usual during the update.
Update: Our load tests over the weekend went well. Next, we will do discrepancy validation tests between our current version and the patch versions. When those pass, we will do a final confirmation with the BeeGFS vendor. We hope to deploy the patch to Wynton in a few days.
Update: After a few rounds, we now have a patch that we have confirmed work on our test BeeGFS system. The plan is to do additional high-load testing today and over the weekend.
Update: The BeeGFS vendors will send us a patch by tomorrow Tuesday, which we will test on our separate BeeGFS test system. After being validated there, will will deploy it to the main system. We hope to have a patch deploy by the end of the week.
Update: We have re-enabled the job scheduler after manually having resolved the BeeGFS meta server issues. We will keep monitoring the problem and send more debug data to the BeeGFS vendors.
Notice: On Monday 2022-03-28 morning at 10:30 the BeeGFS hung again. We put a hold on the job scheduler for now.
March 26, 2022 #
Job scheduler is disabled due to cooling issues #
Resolved: The compute nodes and the job scheduler are up and running again.
Notice: The job scheduler as disabled and running jobs where terminated on Saturday 2022-03-26 around 09:00. This was done due to an emergency shutdown because the ambient temperature in the data center started to rise around 08:00 and at 09:00 it hit the critical level, where our monitoring system automatically shuts down compute nodes to prevent further damage. This resulted in the room temperature coming down to normal levels again. We are waiting on UCSF Facilities to restore cooling in the data center.
March 26, 2022 #
Major BeeGFS issues #
Resolved: Just after 03:00 on Saturday 2022-03-26 morning BeeGFS hung. Recover actions were taken at 07:30 and the problem was resolved before 08:00. We have tracked down the problem occur when a user runs more than one rm -r /wynton/path/to/folder concurrently on the same folder. This is a bug in BeeGFS that vendors is aware of.
March 18-22, 2022 #
Job scheduler is disabled because of BeeGFS issues #
Resolved: We have re-enabled the job scheduler, which now processes all queued jobs. We will keep working with the BeeGFS vendor to find a solution to avoid this issue from happening again.
Update: The BeeGFS issue has been identified. We identified a job that appears to trigger a bug in BeeGFS, which we can reproduce. The BeeGFS vendor will work on a bug fix. The good news is that the job script that triggers the problem can be tweaked to avoid hitting the bug. This means we can enable the job scheduler as soon as all BeeGFS metadata servers have synchronized, which we expect to take a few hours.
Update: The BeeGFS file system troubleshooting continues. The job queue is still disabled. You might experience login and non-responsive prompt issues while we troubleshoot this. We have met with the BeeGFS vendors this morning and we are collecting debug information to allow them to troubleshoot the problem on their end. At the same time, we hope to narrow in on the problem further on our end by trying to identify whether there is a particular job or software running on the queue that might cause this. Currently, we have no estimate when this problem will be fixed. We have another call scheduled with the vendor tomorrow morning.
Update: The BeeGFS file system is back online and the cluster can be accessed again. However, we had to put SGE in maintenance mode, which means no jobs will be started until the underlying problem, which is still unknown, has been identified and resolved. The plan is to talk to the BeeGFS vendor as soon as possible after the weekend. Unfortunately, in order to stabilize BeeGFS, we had to kill, at 16:30 today, all running jobs and requeue them on the SGE job scheduler. They are now listed as status ‘Rq’. For troubleshooting purposes, please do not delete any of your ‘Rq’ jobs.
Notification: The Wynton environment cannot be accessed at the moment. This is because the global file system, BeeGFS, is experiencing issues. The problem, which started around 11:45 today, is being investigated.
March 14-15, 2022 #
Brief network outage #
Noticed: UCSF Network IT will be performing maintenance on several network switches in the evening and overnight on Monday March 14. This will not affect jobs running on the cluster. One of the switches is the one which provides Wynton with external network access. When that switch is rebooted, Wynton will be inaccessible for about 15 minutes. This is likely to happen somewhere between 22:00 and 23:00 that evening, but the outage window extends from 21:00 to 05:00 the following morning, so it could take place anywhere in that window.
February 28-March 2, 2022 #
Full downtime #
Resolved: Wynton is available again.
Update: The Wynton environment is now offline for maintenance work.
Clarification: The shutdown will take place early Monday morning February 28, 2022. Also, this is on a Monday and not on a Tuesday (as previously written below).
Update: We confirm that this downtime will take place as scheduled.
Notice: We are planning a full file-system maintenance starting on Tuesday Monday February 28, 2022. As this requires a full shutdown of the cluster environment, we will start decreasing the job queue, on February 14, two weeks prior to the shutdown. On February 14, jobs that requires 14 days or less to run will be launched. On February 15, only jobs that requires 13 days or less will be launched, and so on until the day of the downtime. Submitted jobs that would go into the downtime window if launched, will only be launched after the downtime window.
Operational Summary for 2021 #
-
Full downtime:
- Scheduled: 64 hours = 2.7 days = 0.73%
- Unscheduled: 58 hours = 2.4 days = 0.66%
- Total: 122 hours = 5.1 days = 1.4%
- External factors: 39% of the above downtime, corresponding to 47 hours (=2.0 days), were due to external factors
Scheduled maintenance downtimes #
- Impact: No file access, no compute resources available
- Damage: None
- Occurrences:
- 2021-05-25 (64 hours)
- Total downtime: 64 hours
Scheduled kernel maintenance #
- Impact: Fewer compute nodes than usual until rebooted
- Damage: None
- Occurrences:
- 2021-01-29 (up to 14 days)
- 2021-07-23 (up to 14 days)
- 2021-12-08 (up to 14 days)
Unscheduled downtimes due to power outage #
- Impact: No file access, no compute resources available
- Damage: Running jobs (<= 14 days) failed, file-transfers failed, possible file corruptions
- Occurrences:
- 2021-08-26 (28 hours) - Planned Byers Hall power shutdown failed
- 2021-11-09 (10 hours) - Unplanned PG&E power outage
- Total downtime: 38 hours of which 38 hours were due to external factors
Unscheduled downtimes due to file-system failures #
- Impact: No file access
- Damage: Running jobs (<= 14 days) may have failed, file-transfers may have failed, cluster not accessible
- Occurrences:
- 2021-03-26 (9 hours) - Campus networks issues causing significant BeeGFS slowness
- 2021-07-23 (8 hours) - BeeGFS silently failed disks
- 2021-11-05 (3 hours) - BeeGFS non-responsive
- Total downtime: 20 hours of which 9 hours were due to external factors
Unscheduled downtimes due to other reasons #
- Impact: Less compute resources
- Damage: Running jobs (<= 14 days) may have failed, file-transfers may have failed, cluster not accessible
- Occurrences:
- 2021-04-28 (210 hours) - GPU taken down due to server room cooling issues
- Total downtime: 0 hours
Accounts #
- Number of user account: 1,274 (change: +410 during the year)
December 8-December 23, 2021 #
Kernel maintenance #
Resolved: All compute nodes have been rebooted.
Notice: New operating-system kernels are deployed. Login, data-transfer, and development nodes will be rebooted tomorrow Thursday December 9 at 11:00. Compute nodes will no longer accept new jobs until they have been rebooted. A node will be rebooted as soon as any existing jobs have completed, which may take up to two weeks (maximum runtime). During this update period, there will be fewer than usual slots available on the queues. To follow the progress, see the green ‘Available CPU cores’ curve (target ~12,500 cores) in the graph above.
December 19-21, 2021 #
Globus and data-transfer node issue #
Resolved: Data-transfer node dt1 and Globus file transfers are working again.
Update: Globus file transfers to and from Wynton are not working. This is because Globus relies on the data-transfer node dt1, which is currently down.
Notice: Data-transfer node dt1 has issues. Please use dt2 until resolved. The first report on this problem came yesterday at 21:30.
November 9, 2021 #
Partial outage due to campus power glitch #
Resolved: All hosts have been rebooted and are now up and running.
Notice: There was a brief PG&E power outage early Tuesday November 9 around 01:20. This affected the power on the Mission Bay campus, including the data center housing Wynton. The parts of our system with redundant power were fine, but many of the compute nodes are on PG&E-power only and, therefore, went down. As a result, lots of jobs crashed. We will restart the nodes that crashed manually during the day today.
October 25-26, 2021 #
File-system maintenance #
Resolved: Resynchronization of all file-system meta servers is complete, which concludes the maintenance.
Update: The maintenance work has started.
Notice: We will perform BeeGFS maintenance work starting Monday October 25 at 2:00 pm. During this work, the filesystem might be less performant. We don’t anticipate any downtime.
August 26-September 10, 2021 #
Byers Hall power outage & file-system corruption #
Resolved: The corrupted filesystem has been recovered.
Update: Wynton is back online but the problematic BeeGFS filesystem is kept offline, which affects access to some of the folders and files hosted on /wynton/group/. The file recovery tools are still running.
Partially resolved: Wynton is back online but the problematic BeeGFS filesystem is kept offline, which affects access to some of the folders and files hosted on /wynton/group/. The file recovery tools are still running.
Update: The BeeGFS filesystem recovering attempt keeps running. The current plan is to bring Wynton back online while keeping the problematic BeeGFS filesystem offline.
Update: All of the BeeGFS servers are up and running, but one of the 108 filesystems that make up BeeGFS was corrupted by the sudden power outage. The bad filesystem is part of /wynton/group/. We estimate that 70 TB of data is affected. We are making every possible effort to restore this filesystem, which will take time. While we do so, Wynton will remain down.
Notice: The cluster is down after an unplanned power outage in the main data center. The power is back online but several of our systems, including BeeGFS servers, did not come back up automatically and will require on-site, manual actions.
July 23-July 28, 2021 #
Kernel maintenance #
Resolved: The majority of the compute nodes have been rebooted after only four days, which was quicker than the maximum of 14 days.
Notice: New operating-system kernels are deployed. Login, data-transfer, and development nodes will be rebooted at 13:00 on Friday July 23 at 1:00 pm. Compute nodes will no longer accept new jobs until they have been rebooted. A node will be rebooted as soon as any existing jobs have completed, which may take up to two weeks (maximum runtime). During this update period, there will be fewer than usual slots available on the queues. To follow the progress, see the green ‘Available CPU cores’ curve (target ~10,400 cores) in the graph above.
June 24, 2021 #
Cluster not accessible (due to BeeGFS issues) #
Resolved: Wynton and BeeGFS is back online. The problem was due to failed disks. Unfortunately, about 10% of the space in /wynton/scratch/ went bad, meaning some files are missing or corrupted. It is neither possible to recover them nor identify which files or folders are affected. In other words, expect some oddness if you had data under /wynton/scratch/. There will also be some hiccups over the next several days as we get everything in ZFS and BeeGFS back into an as stable state as possible.
Update: We’re working hard on getting BeeGFS back up. We were not able to recover the bad storage target, so it looks like there will be some data loss on /wynton/scratch/. More updates soon.
Notification: The Wynton environment cannot be accessed at the moment. This is because the global file system, BeeGFS, is experiencing issues since early this morning. The problem is being investigated.
May 25-June 7, 2021 #
Full downtime (major maintenance) #
Resolved: All remaining issues from the downtime have been resolved.
Update: Login node log2 can now be reached from the UCSF Housing WiFi network.
Update: dt2 can now be reached from outside the Wynton cluster.
Update: Login node log2 cannot be reached from the UCSF Housing WiFi network. If you are on that network, use log1 until this has been resolved.
Update: Both data transfer nodes are back online since a while, but dt2 can only be reached from within the Wynton cluster.
Update: A large number of of the remaining compute nodes have been booted up. There are now ~8,600 cores serving jobs.
Update: The development nodes are now back too. For the PHI pilot project, development node pgpudev1 is back up, but pdev1 is still down.
Update: Wynton is partially back up and running. Both login hosts are up (log1 and log2). The job scheduler, SGE, accepts new jobs and and launches queued jobs. Two thirds of the compute node slots are back up serving jobs. Work is done to bring up the the development nodes and the data transfer hosts (dt1 and dt2).
Update: We hit more than a few snags today. Our filesystem, BeeGFS, is up and running, but it still needs some work. The login hosts are up, but SGE is not and neither are the dev nodes. We will continue the work early tomorrow Thursday.
Notice: The Wynton HPC environment will be shut down late afternoon on Tuesday May 25, 2021, for maintenance. We expect the cluster to be back online late Wednesday May 26. To allow for an orderly shutdown of Wynton, the queues have been disabled starting at 3:30 pm on May 25. Between now and then, only jobs whose runtimes end before that time will be able to start. Jobs whose runtimes would run into the maintenance window will remain in the queue.
Preliminary notice: The Wynton HPC cluster will be undergoing a major upgrade on Wednesday May 26, 2021. As usual, starting 15 days prior to this day, on May 11, the maximum job run-time will be decreased on a daily basis so that all jobs finishes in time, e.g. if you submit a job on May 16 with a run-time longer than nine days, it will not be able to scheduled and it will be queued until after the downtime.
June 1-2, 2021 #
Password management outage #
Resolved: Password updates works again.
Notice: Due to technical issues, it is currently not possible to change your Wynton password. If attempted from the web interface, you will get an error on “Password change not successful! (kadmin: Communication failure with server while initializing kadmin interface )”. If attempted using ‘passwd’, you will get “passwd: Authentication token manipulation error”.
April 28 - May 7, 2021 #
Many GPU nodes down (due to cooling issues) #
Resolved: Cooling has been restored and all GPU nodes are back online again.
Update: Half of the GPU nodes that was taken down are back online. Hopefully, the remaining ones can be brought back up tomorrow when the cooling in the server room should be fully functioning again.
Notification: One of Wynton’s ancillary server rooms is having cooling issues. To reduce the heat load in the room, we had to turn off all the Wynton nodes in the room around 09:45 this morning. This affects GPU nodes named msg*gpu* and a few other regular nodes. We estimate that the UCSF Facilities to fix the cooling problem by early next week.
March 26, 2021 #
Cluster not accessible (due to network outage) #
Resolved: The malfunctioning network link between two of Wynton’s data centers, which affected our BeeGFS file system and Wynton HPC as a whole, has been restored.
Notification: Campus network issues causing major Wynton HPC issues including extremely slow access to our BeeGFS file system. This was first reported around 11:30 today. A ticket has been filed with the UCSF Network. ETA is unknown.
January 29-February 12, 2021 #
Kernel maintenance #
Resolved: All compute nodes have been rebooted. A few compute nodes remain offline that has to be rebooted manually, which will be done as opportunity is given.
Notice: New operating-system kernels are deployed. Compute nodes will no longer accept new jobs until they have been rebooted. A node will be rebooted as soon as any existing jobs have completed, which may take up to two weeks (maximum runtime). During this update period, there will be fewer than usual slots available on the queues. To follow the progress, see the green ‘Available CPU cores’ curve (target ~10,400 cores) in the graph above. Login, data-transfer, and development nodes will be rebooted at 13:00 on Monday February 1.
February 1-3, 2021 #
Development node not available #
Resolved: Development node dev2 is available again.
Notice: Development node dev2 is down. It failed to come back up after the kernel upgrade on 2021-02-01. An on-site reboot is planned for Wednesday February 3.
January 28, 2021 #
Server room maintenance #
Notice: The air conditioning system in one of our server rooms will be upgraded on January 28. The compute nodes in this room will be powered down during the upgrade resulting in fewer compute nodes being available on the cluster. Starting 14 days prior to this date, compute nodes in this room will only accept jobs that will finish in time.
Operational Summary for 2020 #
-
Full downtime:
- Scheduled: 123 hours = 5.1 days = 1.4%
- Unscheduled: 91.5 hours = 3.8 days = 1.0%
- Total: 214.5 hours = 8.9 days = 2.4%
- External factors: 12% of the above downtime, corresponding to 26.5 hours (=1.1 days), were due to external factors
Scheduled maintenance downtimes #
- Impact: No file access, no compute resources available
- Damage: None
- Occurrences:
- 2020-08-10 (93 hours)
- 2020-12-07 (30 hours)
- Total downtime: 123 hours
Scheduled kernel maintenance #
- Impact: Fewer compute nodes than usual until rebooted
- Damage: None
- Occurrences:
- 2020-06-11 (up to 14 days)
- 2020-12-11 (up to 14 days)
Unscheduled downtimes due to power outage #
- Impact: No file access, no compute resources available
- Damage: Running jobs (<= 14 days) failed, file-transfers failed, possible file corruptions
- Occurrences:
- None
- Total downtime: 0 hours
Unscheduled downtimes due to file-system failures #
- Impact: No file access
- Damage: Running jobs (<= 14 days) may have failed, file-transfers may have failed, cluster not accessible
- Occurrences:
- 2020-01-22 (2.5 hours) - BeeGFS failure to failed upgrade
- 2020-01-29 (1.0 hours) - BeeGFS non-responsive
- 2020-02-05 (51.5 hours) - Legacy NetApp file system failed
- 2020-05-22 (0.5 hours) - BeeGFS non-responsive to failed upgrade
- 2020-08-19 (1.5 hours) - BeeGFS non-responsive
- 2020-10-21 (3 hours) - BeeGFS non-responsive
- 2020-11-05 (3 hours) - BeeGFS non-responsive
- Total downtime: 63.0 hours
Unscheduled downtimes due to other reasons #
- Impact: Less compute resources
- Damage: Running jobs (<= 14 days) may have failed, file-transfers may have failed, cluster not accessible
- Occurrences:
- 2020-05-28 (26.5 hours) - MSG Data Center outage affecting many GPU compute nodes
- 2020-07-04 (2 hours) - SGE scheduler failed
- 2020-11-04 (288 hours) - ~80 compute nodes lost due to network switch failure
- Total downtime: 28.5 hours of which 26.5 hours were due to external factors
Accounts #
- Number of user account: 864 (change: +386 during the year)
December 8-17, 2020 #
Limited accessibility of Login node log1 #
Resolved: Login node ‘log1.wynton.ucsf.edu’ can again be accessed from outside of the UCSF network.
Notice: Login node ‘log1.wynton.ucsf.edu’ is only accessible from within UCSF network. This is a side effect of the recent network upgrades. We are waiting for The UCSF IT Network to resolve this for us. Until resolved, please use the alternative ‘log2.wynton.ucsf.edu’ login node when connecting from outside of the UCSF network.
December 11-16, 2020 #
Rebooting compute nodes #
Resolved: All compute nodes have been rebooted.
Notice: The new BeeGFS setting introduced during the upgrades earlier this week caused problems throughout the system and we need to roll them back. The compute nodes will no longer take on new jobs until they have been rebooted. A compute node will be automatically rebooted as soon as all of its running jobs have completed. Unfortunately, we have to kill jobs that run on compute nodes that are stalled and suffer from the BeeGFS issues.
December 11, 2020 #
Rebooting login and development nodes #
Resolved: All login and development nodes have been rebooted.
Notice: Login node ‘log1.wynton.ucsf.edu’ and all the development nodes will be rebooted at 4:30 PM today Friday. This is needed in order to roll back the new BeeGFS setting introduced during the upgrades earlier this week.
December 7-8, 2020 #
Major upgrades (full downtime) #
Resolved: The upgrade has been completed. The cluster back online, including all of the login, data-transfer, and development nodes, as well as the majority of the compute nodes. The scheduler is processing jobs again. All hosts now run CentOS 7.9.
Update: The upgrade is paused and will resume tomorrow. We hope to be bring all of the cluster back online by the end of tomorrow. For now, login node ‘log2’ (but not ‘log1’), and data-transfer nodes ‘dt1’, and ‘dt2’ are back online and can be used for accessing files. Development nodes ‘dev1’ and ‘dev3’ are also available (please make sure to leave room for others). The scheduler remains down, i.e. it is is not be possible to submit jobs.
Update: The upgrades have started. Access to Wynton HPC has been disable as of 10:30 this morning. The schedulers stopped launching queued jobs as of 23:30 last night.
Revised notice: We have decided to hold back on upgrading BeeGFS during
the downtime and only focus on the remain parts including operating system
and network upgrades.
The scope of the work is still non-trivial. There is a risk that the
downtime will extend into Thursday December 10. However, if everything go
smoothly, we hope that Wynton HPC will be back up by the end of Monday or
during the Tuesday. There will only be one continuous downtime, that is,
when the cluster comes back up, it will stay up.
Notice: Starting early Monday December 7, the cluster will be powered down
entirely for maintenance and upgrades, which includes upgrading the operating
system, the network, and the BeeGFS file system. We anticipate that the
cluster will be available again by the end of Tuesday December 8, when load
testing of the upgraded BeeGFS file system will start. If these tests fail,
we will have to unroll the BeeGFS upgrade, which in case we anticipate that
the cluster is back online by the end of Wednesday December 9.
November 4-16, 2020 #
Compute nodes not serving jobs (due to network switch failure) #
Resolved: All 74 compute nodes that were taken off the job scheduler on 2020-11-04 are back up and running
Notice: 74 compute nodes, including several GPU nodes, were taken off the job scheduler around 14:00 on 2020-11-04 due to a faulty network switch. The network switch needs to be replaced in order to resolve this.
November 5, 2020 #
Cluster inaccessible (due to BeeGFS issues) #
Resolved: Our BeeGFS file system was non-responsive during 01:20-04:00 on 2020-11-05 because one of the meta servers hung.
October 21, 2020 #
Cluster inaccessible (due to BeeGFS issues) #
Resolved: Our BeeGFS file system was non-responsive because one of its meta servers hung, which now has been restarted.
Notice: The cluster is currently inaccessible for unknown reasons. The problem was first reported around 09:30 today.
August 19, 2020 #
Cluster inaccessible (due to BeeGFS issues) #
Resolved: Our BeeGFS file system was non-responsive between 17:22 and 18:52 today because one of its meta servers hung while the other attempted to synchronize to it.
Notice: The cluster is currently inaccessible for unknown reasons. The problem was first reported around 17:30 today.
August 10-13, 2020 #
Network and hardware upgrades (full downtime) #
Resolved: The cluster is fully back up and running. Several compute nodes still need to be rebooted but we consider this upgrade cycle completed. The network upgrade took longer than expected, which delayed the processes. We hope to bring the new lab storage online during the next week.
Update: All login, data-transfer, and development nodes are online.
Additional compute nodes are being upgraded and are soon part of the
pool serving jobs.
Update: Login node log1, data-transfer node dt2, and the development nodes
are available again. Compute nodes are going through an upgrade cycle and
will soon start serving jobs again. The upgrade work is taking longer than
expected and will continue tomorrow Thursday August 13.
Notice: All of the Wynton HPC environment is down for maintenance
and upgrades.
Notice: Starting early Monday August 10, the cluster will be powered down
entirely for maintenance and upgrades, which includes upgrading the network
and adding lab storage purchased by several groups. We anticipate that
the cluster will be available again by the end of Wednesday August 12.
July 6, 2020 #
Development node failures #
Resolved: All three development nodes have been rebooted.
Notice: The three regular development nodes have all gotten themselves hung up on one particular process. This affects basic system operations and preventing such basic commands as ps and w. To clear this state, we’ll be doing an emergency reboot of the dev nodes at about 15:15.
July 5, 2020 #
Job scheduler non-working #
Resolved: The SGE scheduler produced errors when queried or when jobs were submitted or launched. The problem started 00:30 and lasted until 02:45 early Sunday 2020-07-05.
June 11-26, 2020 #
Kernel maintenance #
Resolved: All compute nodes have been rebooted.
Update: Development node dev3 is back online.
Update: Development node dev3 is not available. It failed to reboot and requires on-site attention, which might not be possible for several days. All other log-in, data-transfer, and development nodes were rebooted successfully.
Notice: New operating-system kernels are deployed. Compute nodes will no longer accept new jobs until they have been rebooted. A node will be rebooted as soon as any existing jobs have completed, which may take up to two weeks (maximum runtime). During this update period, there will be fewer than usual slots available on the queues. To follow the progress, see the green ‘Available CPU cores’ curve (target ~10,400 cores) in the graph above. Log-in, data-transfer, and development nodes will be rebooted at 15:30 on Thursday June 11.
June 5-9, 2020 #
No internet access on development nodes #
Resolved: Internet access from the development nodes is available again. A new web-proxy server had to be built and deploy.
Notice: Internet access from the development nodes is not available. This is because the proxy server providing them with internet access had a critical hardware failure around 08-09 this morning. At the most, we cannot provide an estimate when we get to restore this server.
May 18-22, 2020 #
File-system maintenance #
Update: The upgrade of the BeeGFS filesystem introduced new issues.
We decided to rollback the upgrade and we are working with the vendor.
There is no upgrade planned for the near term.
Update: The BeeGFS filesystem has been upgraded using a patch from the
vendor. The patch was designed to lower the amount of resynchronization needed
between the two metadata servers. Unfortunately, after the upgrade we observe
an increase of resynchronization. We will keep monitoring the status. If
the problem remains, we will consider a rollback to the BeeGFS version used
prior to May 18.
Update: For a short moment around 01:00 early Friday, both of our BeeGFS
metadata servers were down. This may have lead to some applications
experiencing I/O errors around this time.
Notice: Work to improve the stability of the BeeGFS filesystem (/wynton)
will be conducted during the week of May 18-22. This involves restarting the
eight pairs of metadata server processes, which may result in several brief
stalls of the file system. Each should last less than 5 minutes and operations
will continue normally after each one.
May 28-29, 2020 #
GPU compute nodes outage #
Resolved: The GPU compute nodes are now fully available to serve jobs.
Update: The GPU compute nodes that went down yesterday have been rebooted.
Investigating: A large number of GPU compute nodes in the MSG data center are currently down for unknown reasons. We are investigating the cause.
February 5-7, 2020 #
Major outage due to NetApp file-system failure #
Resolved: The Wynton HPC system is considered fully functional again. The legacy, deprecated NetApp storage was lost.
Update: The majority of the compute nodes have been rebooted and are now online and running jobs. We will actively monitor the system and assess the how everything works before we considered this incident resolved.
Update: The login, development and data transfer nodes will be rebooted at 01:00 today Friday February 7.
Update: The failed legacy NetApp server is the cause to the problems, e.g. compute nodes not being responsive causing problems for SGE etc. Because of this, all of the cluster - login, development, transfer, and computes nodes - will be rebooted tomorrow Friday 2020-02-07.
Notice: Wynton HPC is experience major issues due to NetApp file-system failure, despite this is being deprecated and not used much these days. The first user report on this came in around 09:00 and the job-queue logs suggests the problem began around 02:00. It will take a while for everything to come back up and there will be brief BeeGFS outage while we reboot the BeeGFS management node.
January 29, 2020 #
BeeGFS failure #
Resolved: The BeeGFS file-system issue has been resolved by rebooting two meta servers.
Notice: There’s currently an issue with the BeeGFS file system. Users reporting that they cannot log in.
January 22, 2020 #
File-system maintenance #
Resolved: The BeeGFS upgrade issue has been resolved.
Update: The planned upgrade caused unexpected problems to the BeeGFS file system resulting in /wynton/group becoming unstable.
Notice: One of the BeeGFS servers, which serve our cluster-wide file system, will be swapped out starting at noon (11:59am) on Wednesday January 22, 2020 and the work is expected to last one hour. We don’t anticipate any downtime because the BeeGFS servers are mirrored for availability.
December 20, 2019 - January 4, 2020 #
Kernel maintenance #
Resolved: All compute nodes have been updated and rebooted.
Notice: Compute nodes will no longer accept new jobs until they have been rebooted. A node will be rebooted as soon as any existing jobs have completed, which may take up to two weeks (maximum runtime). During this update period, there will be fewer available slots on the queues than usual. To follow the progress, see the green ‘Available CPU cores’ curve (target ~7,500 cores) in the graph above. Log-in, data-transfer, and development nodes will be rebooted at 15:30 on Friday December 20. GPU nodes already run the new kernel and are not affected.
Operational Summary for 2019 #
-
Full downtime:
- Scheduled: 96 hours = 4.0 days = 1.1%
- Unscheduled: 83.5 hours = 3.5 days = 1.0%
- Total: 179.5 hours = 7.5 days = 2.0%
- External factors: 15% of the above downtime, corresponding to 26 hours (=1.1 days), were due to external factors
Scheduled maintenance downtimes #
- Impact: No file access, no compute resources available
- Damage: None
- Occurrences:
- 2021-01-09 (1.0 hours) - job scheduler updates
- 2021-07-08 (95 hours)
- Total downtime: 96.0 hours
Scheduled kernel maintenance #
- Impact: Fewer compute nodes than usual until rebooted
- Damage: None
- Occurrences:
- 2019-01-22 (up to 14 days)
- 2019-03-21 (up to 14 days)
- 2019-10-29 (up to 14 days)
- 2019-12-22 (up to 14 days)
Unscheduled downtimes due to power outage #
- Impact: No file access, no compute resources available
- Damage: Running jobs (<= 14 days) failed, file-transfers failed, possible file corruptions
- Occurrences:
- 2019-07-30 (6.5 hour) - Byers Hall power outage
- 2019-08-15 (5.5 hour) - Diller power outage
- 2019-10-25 (1.0 hour) - Byers Hall power outage
- 2019-10-22 (13.0 hour) - Diller power backup failed during power maintenance
- Total downtime: 26.0 hours of which 26.0 hours were due to external factors
Unscheduled downtimes due to file-system failures #
- Impact: No file access
- Damage: Running jobs (<= 14 days) may have failed, file-transfers may have failed, cluster not accessible
- Occurrences:
- 2019-01-08 (2.0 hours) - BeeGFS server non-responsive
- 2019-01-14 (1.5 hours) - BeeGFS non-responsive
- 2019-05-15 (24.5 hours) - BeeGFS non-responsive
- 2019-05-17 (5.0 hours) - BeeGFS slowdown
- 2019-06-17 (10.5 hours) - BeeGFS non-responsive
- 2019-08-23 (4.0 hours) - BeeGFS server non-responsive
- 2019-09-24 (3.0 hours) - BeeGFS server non-responsive
- 2019-12-18 (3.5 hours) - Network switch upgrade
- 2019-12-22 (5.5 hours) - BeeGFS server non-responsive
- Total downtime: 58.5 hours of which 0 hours were due to external factors
Accounts #
- Number of user account: 478 (change: +280 during the year)
December 20, 2019 - January 4, 2020 #
Kernel maintenance #
Resolved: All compute nodes have been updated and rebooted.
Notice: Compute nodes will no longer accept new jobs until they have been rebooted. A node will be rebooted as soon as any existing jobs have completed, which may take up to two weeks (maximum runtime). During this update period, there will be fewer available slots on the queues than usual. To follow the progress, see the green ‘Available CPU cores’ curve (target ~7,500 cores) in the graph above. Log-in, data-transfer, and development nodes will be rebooted at 15:30 on Friday December 20. GPU nodes already run the new kernel and are not affected.
December 22, 2019 #
BeeGFS failure #
Resolved: No further hiccups were needed during the BeeGFS resynchronization. Everything is working as expected.
Update: The issues with login was because the responsiveness of one of the BeeGFS file servers became unreliable around 04:20. Rebooting that server resolved the problem. The cluster is fully functional again although slower than usual until the file system have been resynced. After this, there might be a need for one more, brief, reboot.
Notice: It is not possible to log in to the Wynton HPC environment. The reason is currently not known.
December 18, 2019 #
Network/login issues #
Resolved: The Wynton HPC environment is fully functional again. The BeeGFS filesystem was not working properly during 18:30-22:10 on December 18 resulting in no login access to the cluster and job file I/O being backed up.
Update: The BeeGFS filesystem is non-responsive, which we believe is due to the network switch upgrade.
Notice: One of two network switches will be upgraded on Wednesday December 18 starting at 18:00 and lasting a few hours. We do not expect this to impact the Wynton HPC environment other than slowing down the network performance to 50%.
October 29-November 11, 2019 #
Kernel maintenance #
Resolved: All compute nodes have been updated and rebooted.
Notice: Compute nodes will no longer accept new jobs until they have been rebooted. A node will be rebooted as soon as any existing jobs have completed, which may take up to two weeks (maximum runtime). GPU nodes will be rebooted as soon as all GPU jobs complete. During this update period, there will be fewer available slots on the queues than usual. To follow the progress, see the green ‘Available CPU cores’ curve (target ~7,000 cores) in the graph above.
October 25, 2019 #
Byers Hall power outage glitch #
Resolved: Development node qb3-dev2 was rebooted. Data-transfer node dt1.wynton.ucsf.edu is kept offline because it is scheduled to be upgraded next week.
Update: Most compute nodes that went down due to the power glitch has been rebooted. Data-transfer node dt1.wynton.ucsf.edu and development node qb3-dev2 are still down - they will be brought back online on Monday October 28.
Notice: A very brief power outage in the Byers Hall building caused several compute nodes in its Data Center to go down. Jobs that were running on those compute nodes at the time of the power failure did unfortunately fail. Log-in, data-transfer, and development nodes were also affected. All these hosts are currently being rebooted.
October 24, 2019 #
Login non-functional #
Resolved: Log in works again.
Notice: It is not possible to log in to the Wynton HPC environment. This is due to a recent misconfiguration of the LDAP server.
October 22-23, 2019 #
BeeGFS failure #
Resolved: The Wynton HPC BeeGFS file system is fully functional again. During the outage, /wynton/group and /wynton/scratch was not working properly, whereas /wynton/home was unaffected.
Notice: The Wynton HPC BeeGFS file system is non-functional. It is expected to be resolved by noon on October 23. The underlying problem is that the power backup at the Diller data center did not work as expected during a planned power maintenance.
September 24, 2019 #
BeeGFS failure #
Resolved: The Wynton HPC environment is up and running again.
Notice: The Wynton HPC environment is unresponsive. Problem is being investigated.
August 23, 2019 #
BeeGFS failure #
Resolved: The Wynton HPC environment is up and running again. The reason for this downtime was the BeeGFS file server became unresponsive.
Notice: The Wynton HPC environment is unresponsive.
August 15, 2019 #
Power outage #
Resolved: The Wynton HPC environment is up and running again.
Notice: The Wynton HPC environment is down due to a non-planned power outage at the Diller data center. Jobs running on compute nodes located in that data center, were terminated. Jobs running elsewhere may also have been affected because /wynton/home went down as well (despite it being mirrored).
July 30, 2019 #
Power outage #
Resolved: The Wynton HPC environment is up and running again.
Notice: The Wynton HPC environment is down due to a non-planned power outage at the main data center.
July 8-12, 2019 #
Full system downtime #
Resolved: The Wynton HPC environment and the BeeGFS file system are fully functional after updates and upgrades.
Notice: The Wynton HPC environment is down for maintenance.
Notice: Updates to the BeeGFS file system and the operating system that require to bring down all of Wynton HPC will start on the morning of Monday July 8. Please make sure to log out before then. The downtime might last the full week.
June 17-18, 2019 #
Significant file-system outage #
Resolved: The BeeGFS file system is fully functional again.
Investigating: Parts of /wynton/scratch and /wynton/group are currently unavailable. The /wynton/home space should be unaffected.
May 17, 2019 #
Major outage due to file-system issues #
Resolved: The BeeGFS file system and the cluster is functional again.
Investigating: There is a major slowdown of the BeeGFS file system (/wynton), which in turn causes significant problems throughout the Wynton HPC environment.
May 15-16, 2019 #
Major outage due to file-system issues #
Resolved: The BeeGFS file system, and thereby also the cluster itself, is functional again.
Investigating: The BeeGFS file system (/wynton) is experiencing major issues. This caused all on Wynton HPC to become non-functional.
May 15, 2019 #
Network/login issues #
Resolved: The UCSF-wide network issue that affected access to Wynton HPC has been resolved.
Update: The login issue is related to UCSF-wide network issues.
Investigating: There are issues logging in to Wynton HPC.
March 21-April 5, 2019 #
Kernel maintenance #
Resolved: All compute nodes have been rebooted.
Update: Nearly all compute nodes have been rebooted (~5,200 cores are now available).
Notice: Compute nodes will no longer accept new jobs until they have been rebooted. A node will be rebooted as soon as any existing jobs have completed, which may take up to two weeks (maximum runtime). During this update period, there will be fewer available slots on the queues than usual. To follow the progress, see the green ‘Available CPU cores’ curve (target 5,424 cores) in the graph above.
March 22, 2019 #
Kernel maintenance #
Resolved: The login, development and transfer hosts have been rebooted.
Notice: On Friday March 22 at 10:30am, all of the login, development, and data transfer hosts will be rebooted. Please be logged out before then. These hosts should be offline for less than 5 minutes.
January 22-February 5, 2019 #
Kernel maintenance #
Resolved: All compute nodes have been rebooted.
Notice: Compute nodes will no longer accept new jobs until they have been rebooted. A node will be rebooted as soon as any existing jobs have completed, which may take up to two weeks (maximum runtime). During this update period, there will be fewer available slots on the queues than usual. To follow the progress, see the green ‘Available CPU cores’ curve (target 1,944 cores) in the graph above.
January 23, 2019 #
Kernel maintenance #
Resolved: The login, development and transfer hosts have been rebooted.
Notice: On Wednesday January 23 at 12:00 (noon), all of the login, development, and data transfer hosts will be rebooted. Please be logged out before then. The hosts should be offline for less than 5 minutes.
January 14, 2019 #
Blocking file-system issues #
Resolved: The file system under /wynton/ is back up again. We are looking into the cause and taking steps to prevent this from happening again.
Investigating: The file system under /wynton/ went down around 11:30 resulting is several critical failures including the scheduler failing.
January 9, 2019 #
Job scheduler maintenance downtime #
Resolved: The SGE job scheduler is now back online and accepts new job submission again.
Update: The downtime of the job scheduler will begin on Wednesday January 9 @ noon and is expected to be completed by 1:00pm.
Notice: There will be a short job-scheduler downtime on Wednesday January 9 due to SGE maintenance. During this downtime, already running jobs will keep running and queued jobs will remain in the queue, but no new jobs can be submitted.
January 8, 2019 #
File-system server crash #
Investigating: One of the parallel file-system servers (BeeGFS) appears to have crashed on Monday January 7 at 07:30 and was recovered on 9:20pm. Right now we are monitoring its stability, and investigating the cause and what impact it might have had. Currently, we believe users might have experienced I/O errors on /wynton/scratch/ whereas /wynton/home/ was not affected.
Operational Summary for 2018 Q3-Q4 #
-
Full downtime:
- Scheduled: 0 hours = 0.0%
- Unscheduled: 84 hours = 3.5 days = 1.9%
- Total: 84 hours = 3.5 days = 1.9%
- External factors: 100% of the above downtime, corresponding to 84 hours (=3.5 days), were due to external factors
Scheduled maintenance downtimes #
- Impact: No file access, no compute resources available
- Damage: None
- Occurrences:
- None
- Total downtime: 0.0 hours
Scheduled kernel maintenance #
- Impact: Fewer compute nodes than usual until rebooted
- Damage: None
- Occurrences:
- 2018-09-28 (up to 14 days)
Unscheduled downtimes due to power outage #
- Impact: No file access, no compute resources available
- Damage: Running jobs (<= 14 days) failed, file-transfers failed, possible file corruptions
- Occurrences:
- 2018-06-17 (23 hours) - Campus power outage
- 2018-11-08 (19 hours) - Byers Hall power maintenance without notice
- 2018-12-14 (42 hours) - Sandler Building power outage
- Total downtime: 84 hours of which 84 hours were due to external factors
Unscheduled downtimes due to file-system failures #
- Impact: No file access
- Damage: Running jobs (<= 14 days) may have failed, file-transfers may have failed, cluster not accessible
- Occurrences:
- None.
- Total downtime: 0.0 hours
Accounts #
- Number of user account: 198 (change: +103 during the year)
December 21, 2018 #
Partial file system failure #
Resolved: Parts of the new BeeGFS file system was non-functional for approx. 1.5 hours during Friday December 21 when a brief maintenance task failed.
December 12-20, 2018 #
Nodes down #
Resolved: All of the `msg-* compute nodes but one are operational.
Notice: Starting Wednesday December 12 around 11:00, several msg-* compute nodes went down (~200 cores in total). The cause of this is unknown. Because it might be related to the BeeGFS migration project, the troubleshooting of this incident will most likely not start until the BeeGFS project is completed, which is projected to be done on Wednesday December 19.
December 18, 2018 #
Development node does not respond #
Resolved: Development node qb3-dev1 is functional.
Investigating: Development node qb3-dev1 does not respond to SSH. This will be investigated the first thing tomorrow morning (Wednesday December 19). In the meanwhile, development node qb3-gpudev1, which is “under construction”, may be used.
November 28-December 19, 2018 #
Installation of new, larger, and faster storage space #
Resolved: /wynton/scratch is now back online and ready to be used.
Update: The plan is to bring /wynton/scratch back online before the end of the day tomorrow (Wednesday December 19). The planned SGE downtime has been rescheduled to Wednesday January 9. Moreover, we will start providing the new 500-GiB /wynton/home/ storage to users who explicitly request it (before Friday December 21) and who also promise to move the content under their current /netapp/home/ to the new location. Sorry, users on both QB3 and Wynton HPC will not be able to migrate until the QB3 cluster has been incorporated into Wynton HPC (see Roadmap) or they giving up their QB3 account.
Update: The installation and migration to the new BeeGFS parallel file servers is on track and we expect to go live as planned on Wednesday December 19. We are working on fine tuning the configuration, running performance tests, and resilience tests.
Update: /wynton/scratch has been taken offline.
Reminder: All of /wynton/scratch will be taken offline and completely wiped starting Wednesday December 12 at 8:00am.
Notice: On Wednesday December 12, 2018, the global scratch space /wynton/scratch will be taken offline and completely erased. Over the week following this, we will be adding to and reconfiguring the storage system in order to provide all users with new, larger, and faster (home) storage space. The new storage will served using BeeGFS, which is a new much faster file system - a system we have been prototyping and tested via /wynton/scratch. Once migrated to the new storage, a user’s home directory quota will be increased from 200 GiB to 500 GiB. In order to do this, the following upgrade schedule is planned:
-
Wednesday November 28-December 19 (21 days): To all users, please refrain from using
/wynton/scratch- use local, node-specific/scratchif possible (see below). The sooner we can take it down, the higher the chance is that we can get everything in place before December 19. -
Wednesday December 12-19 (8 days):
/wynton/scratchwill be unavailable and completely wiped. For computational scratch space, please use local/scratchunique to each compute node. For global scratch needs, the old and much slower/scrappand/scrapp2may also be used. -
Wednesday December 19, 2018 (1/2 day): The Wynton HPC scheduler (SGE) will be taken offline. No jobs will be able to be submitted until it is restarted. -
Wednesday December 19, 2018: The upgraded Wynton HPC with the new storage will be available including
/wynton/scratch. -
Wednesday January 9, 2019 (1/2 day): The Wynton HPC scheduler (SGE) will be taken offline temporarily. No jobs will be able to be submitted until it is restarted.
It is our hope to be able to keep the user’s home accounts, login nodes, the transfer nodes, and the development nodes available throughout this upgrade period.
NOTE: If our new setup proves more challenging than anticipated, then we will postpone the SGE downtime to after the holidays, on Wednesday January 9, 2019. Wynton HPC will remain operational over the holidays, though without /wynton/scratch.
December 12-14, 2018 #
Power failure #
Resolved: All mac-* compute nodes are up and functional.
Investigating: The compute nodes named mac-* (in the Sandler building) went down due to power failure on Wednesday December 12 starting around 05:50. Nodes are being rebooted.
November 8, 2018 #
Partial shutdown due to planned power outage #
Resolved: The cluster is full functional. It turns out that none of the compute nodes, and therefore none of the running jobs, were affected by the power outage.
Update: The queue-metric graphs are being updated again.
Update: The login nodes, the development nodes and the data transfer node are now functional.
Update: Login node wynlog1 is also affected by the power outage. Use wynlog2 instead.
Notice: Parts of the Wynton HPC cluster will be shut down on November 8 at 4:00am. This shutdown takes place due to the UCSF Facilities shutting down power in the Byers Hall. Jobs running on affected compute nodes will be terminated abruptly. Compute nodes with battery backup or in other buildings will not be affected. Nodes will be rebooted as soon as the power comes back. To follow the reboot progress, see the ‘Available CPU cores’ curve (target 1,832 cores) in the graph above. Unfortunately, the above queue-metric graphs cannot be updated during the power outage.
September 28 - October 11, 2018 #
Kernel maintenance #
Resolved: The compute nodes has been rebooted and are accepting new jobs. For the record, on day 5 approx. 300 cores were back online, on day 7 approx. 600 cores were back online, on day 8 approx. 1,500 cores were back online, and on day 9 the majority of the 1,832 cores were back online.
Notice: On September 28, a kernel update was applied to all compute nodes. To begin running the new kernel, each node must be rebooted. To achieve this as quickly as possible and without any loss of running jobs, the queues on the nodes were all disabled (i.e., they stopped accepting new jobs). Each node will reboot itself and re-enable its own queues as soon as all of its running jobs have completed. Since the maximum allowed run time for a job is two weeks, it may take until October 11 before all nodes have been rebooted and accepting new jobs. In the meanwhile, there will be fewer available slots on the queue than usual. To follow the progress, see the ‘Available CPU cores’ curve (target 1,832 cores) in the graph above.
October 1, 2018 #
Kernel maintenance #
Resolved: The login, development, and data transfer hosts have been rebooted.
Notice: On Monday October 1 at 01:00, all of the login, development, and data transfer hosts will be rebooted.
September 13, 2018 #
Scheduler unreachable #
Resolved: Around 11:00 on Wednesday September 12, the SGE scheduler (“qmaster”) became unreachable such that the scheduler could not be queried and no new jobs could be submitted. Jobs that relied on run-time access to the scheduler may have failed. The problem, which was due to a misconfiguration being introduced, was resolved early morning on Thursday September 13.
August 1, 2018 #
Partial shutdown #
Resolved: Nodes were rebooted on August 1 shortly after the power came back.
Notice: On Wednesday August 1 at 6:45am, parts of the compute nodes (msg-io{1-10} + msg-*gpu) will be powered down. They will be brought back online within 1-2 hours. The reason is a planned power shutdown affecting one of Wynton HPC’s server rooms.
July 30, 2018 #
Partial shutdown #
Resolved: The nodes brought down during the July 30 partial shutdown has been rebooted. Unfortunately, the same partial shutdown has to be repeated within a few days because the work in server room was not completed. Exact date for the next shutdown is not known at this point.
Notice: On Monday July 30 at 7:00am, parts of the compute nodes (msg-io{1-10} + msg-*gpu) will be powered down. They will be brought back online within 1-2 hours. The reason is a planned power shutdown affecting one of Wynton HPC’s server rooms.
June 16-26, 2018 #
Power outage #
Resolved: The Nvidia-driver issue occurring on some of the GPU compute nodes has been fixed.
Update: Some of the compute nodes with GPUs are still down due to issues with the Nvidia drivers.
Update: The login nodes and and the development nodes are functional. Some compute nodes that went down are back up, but not all.
Investigating: The UCSF Mission Bay Campus experienced a power outage on Saturday June 16 causing parts of Wynton HPC to go down. One of the login nodes (wynlog1), the development node (qb3-dev1), and parts of the compute nodes are currently non-functional.